説明¶
皆さんは,ジグソーパズルで遊んだことがあるだろう。そう、一枚の写真を細かく分割したパズルピースを正しく組み合わせて元の写真を作るあのゲームである。さて、あなたは どうやってパズルを解くだろうか? あなたのやり方をプログラムにしてみれば、コンピュータはジグソーパズルを解けるだろうか? もしもコンピュータがジグソーパズルを解けるとしよう。そうであれば,大量の自然画像をコンピュータに与えれば、コンピュータはたくさんの画像を自然につなげて更に大きな画像を作れるようになるだろうか? もしコンピュータが複数枚の自然画像をつなげることができるなら,大量の画像から被写体の3次元モデルを作成する事は可能だろうか?
疑問と想像は尽きない.しかしこれらの質問は全て最も基本的な質問に依存している.どうやってジグソーパズルを解くのだろうか?どうやって大量のごちゃごちゃした画像のピースを一枚の大きな画像に組み合わせるのか、どのようにして大量の自然画像をどのようにつなぎあわせて大きな一枚の画像を作るのだろうか?
その答えは...我々はユニークかつ追跡・比較が容易な特定のパターン、もしくは特徴を探している.そのような特徴の定義を言葉で説明するのは難しいが,どのようなものなのか頭の中ではわかっている.もしも誰かが、複数枚の画像に共通して比較のために使える良い特徴を尋ねたとしたら,あなたはこれだと指定できるだろう.これが小さな子供でさえジグソーパズルなどができる理由である.画像の中からそのような特徴を探し,別の画像の中から同じ特徴を探して揃える、それだけである(ジグソーパズルでは、異なる画像の連続性も考慮するが).これら全ての能力は我々が固有に持っている能力である.
このように、根本的な疑問から出発して疑問がどんどん増えてきたが,しかしながらその疑問はより特定されてきた.それは、 この特徴とは何なのか ということだ (そして、この答えはコンピュータにも理解できなければならない)
このような特徴をどのようにして人間が見つけているかを説明するのは難しい.我々の脳で既にプログラムされているものだからだ。しかし、幾つか写真を注意深く観察し、そこでいろいろなパターンを探してみれば、なにか興味深いものが見つかるだろう.例えば次の画像を見てみよう:

この画像はすっきりしており、ごちゃごちゃしたところはない.ただし、この画像の上に6個のパッチを置いてある.そこであなたへの質問である:このパッチはこの画像のどこにあるだろうか。あなたはいくつ正解を見つけられるだろうか? (注意: パッチを切り取り、画像の上でパッチを動かして、同じように見えるかどうか、という調べ方を以下では想定している)
パッチAとBはテクスチャが平坦で,画像中の色々な場所にみつかる。だからこれらのパッチが厳密にどこにあるか見つけるのは難しい.
パッチCとDを見つけるのはだいぶ楽である.これらは建物の縁(エッジ)である。だいたいの位置は分かるだろう。しかし、厳密な位置となると見つけるのはなおも難しい.エッジに沿った点はみな同じように見えるからである。エッジの法線方向に見ると違って見える.つまり,エッジはテクスチャが平坦な領域(AやB)と比べればはるかに位置の同定をしやすい特徴だが,それでも厳密な位置について十分な情報を与えてくれるわけではない(ジグソーパズルでは、エッジが続いているかどうかの比較にはよいだろう).
最後に、パッチEとFは建物の角(コーナー)を写したパッチである。そして簡単に画像のどこにあるか、見つけ出すことができる.コーナーなので、このパッチを動かしてみれば見え方が変わるからである.従って,コーナーはよい特徴と考えられる.さてそれでは、さらに理解を深めるために、もっと単純(で、より広く使われている)画像へと話を移すことにしよう.
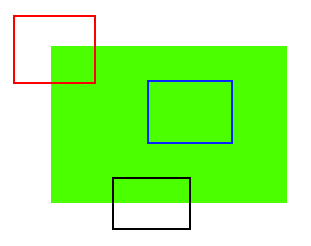
先の画像と同様,青線で囲まれた矩形領域(「青パッチ」と呼ぶ)はテクスチャが平坦な領域で、検出・追跡が難しい領域である.青パッチをどこに動かしても同じように見えてしまう.黒線で囲まれた矩形領域(黒パッチと呼ぶ)は、エッジ上に存在する.縦方向(勾配方向)に動かせば見え方が変化するが,エッジに平行に動かすと見え方は変化しない.赤線で囲まれた矩形領域(「赤パッチ」)はコーナーなので,どの方向に動かしても異なった見え方になる,つまり.基本的にコーナーは画像中の良い特徴とみなせるわけである(コーナーだけではなく,シミ状領域(blob)も良い特徴とみなせることがある).
これで前の疑問”良い特徴とは何か”に対して答えが見つかった.しかし,今度は別の疑問が湧いてくる.どうやってこのような良い特徴を見つけられるだろうか?どうやってコーナーを見つけるのだろうか? これには直観的な方法で答えよう.画像中の小領域を見て,その周囲の領域で微小な移動を加えた時に最大の分散を示す領域を見つければ良いのである.以後のチュートリアルでこの直観的な説明をコンピュータ用語に置き換えていく.これらの画像特徴を見つけることを Feature Detection(特徴検出) と言う.
ある画像でなんらかの特徴を見つけたとする。そうしたら、他の画像でもそれと同じ特徴も見つけられないといけない.そのためには何をすればよいのだろうか?それには、特徴の周囲の領域を取り出し、我々自身の言葉で”上の方は青い空,下の方は建物があり,建物にはガラスがあって...”というように説明し,他の画像にもこれと同じような領域があるか探せばよい.この記述は Feature Description(特徴量記述) と呼ばれる.このような特徴点と特徴量を得られれば,あらゆる画像の中から同じ特徴を見つけることができ,共通する特徴点を基に画像の位置合わせや繋ぎあわせなど、色々な事ができるようになる.
このチュートリアルでは,OpenCVが提供する様々な特徴点検出器,特徴量記述子,特徴点のマッチングについて学んでいく.