Pandas
pandas(「パンダズ」と読む)は、データ解析を容易にする機能を提供するPythonのライブラリです。これは、データフレーム(DataFrame)などのデータ構造と、それらのデータ構造に対する様々な処理を施す機能を提供しています。時系列データや階層型インデックスの扱いに優れ、Numpyと連携し、MatPlotLibを利用した可視化ツールを持ち、計算の高速化も考慮して設計されています。
Pandasを使うには、まず次のようにしてpandasパッケージをimport(取り込む)必要があります:
import pandas as pd
import numpy as np # numpyと連携して動作するため
Pandasのデータ構造
Pandasには、プログラムで作成したデータや外部から読み込んだデータを保持するためのデータ構造として、シリーズ、データフレーム、パネルという三つの形式があります。ここでは最もよく使われるデータフレームについて紹介します。
データフレーム(DataFrame)
データフレームはエクセルファイルのような2次元のラベル付きのデータ構造です。それぞれの行と列に名前(ラベル)を付けることができ、それぞれ行ラベル(index)と列ラベル(columns)といいます。そして列ごとに、数値、文字列、ブール値など別々の型の値を持たせることができます。
データフレームを作成するにはいろいろな方法がありますが、もっとも一般的な方法は、まず辞書を用意し、それぞれのキーに同じ長さを持つリストを値として対応させる、というものです。その例を以下に示します。
data = {'city' : ['Kyoto', 'Nagoya', 'Osaka', 'Yokohama'], 'population':[1.5, 2.3, 2.7, 3.7],
'prefecture' :['Kyoto', 'Aichi','Osaka','Kanagawa']} # それぞれのキーが長さ4のリストを値とする辞書を作成。
df1 = pd.DataFrame(data) # 辞書dataを基にデータフレームを作る
print(df1.columns) # データフレームdf1の列ラベルの表示
df1 # Notebookではデータフレームは表として表示される
作成されたデータフレームには自動的にインデックス(行ラベル)が割り当てられます。また列の順序も自動で並び替え(ソート)されます。ただし、データフレーム作成の時にcolumns引数を指定すれば、列の順番を固定できます。
df1 = pd.DataFrame(data, columns=['city','prefecture','population']) # データフレームを作る
print(df1.columns) # 列ラベルの表示
df1 # Notebookではデータフレームは表として表示される
インデックス(行ラベル)も次のようにして付け替えることができます。
df1.index = [4,3,2,1]
df1 # Notebookではデータフレームは表として表示される
データフレーム生成時に、対応するデータがない列ラベルを指定した時にはエラーにはならずに、その列の値として NaN (「非数値(Not a Number)」、この場合は値が欠損していることを意味)が割り当てられます。
df1 = pd.DataFrame(data, columns=['city','population','prefecture','year']) # データフレームを作る
print(df1.columns) # 列ラベルの表示
df1 # Notebookではデータフレームは表として表示される
データフレームの列は、辞書式の参照方法や属性指定により取り出すことができます。取り出された1次元のデータは「シリーズ(Series)」と呼ばれています。この列データは、元のデータフレームが持っていたインデックスと同じインデックスを持ち、ラベル(name)も保持されています。
s1 = df1['city'] # 辞書式の参照方法
print(s1)
s2 = df1.city # 属性指定
print(s2)
列の値は修正することができます。次の例のように、列にスカラー値や配列を代入して修正することが可能です。
df1.year = 1956 # 大都市の政令指定年
df1 # Notebookではデータフレームは表として表示される
存在しない列に代入を行うと、新たな列が作られます。逆にdelキーワードにより列を削除することができます。
df1['region']=['近畿', '中部', '近畿', '関東']
df1 # Notebookではデータフレームは表として表示される
del df1['year']
df1 # Notebookではデータフレームは表として表示される
データの管理
pandasオブジェクトは、以下に示すようないろいろな方法で結合させることができます。- pandas.merge関数は、データフレームに含まれる行を、1つ以上のキーでマージすることができます。
- pandas.concat関数は、複数の列のオブジェクトを貼りわせたり、積み上げたりすることができます。
- combine_first というインスタンス・メソッドは、複数のオブジェクト間で重複する部分のデータを繋ぎあわせて、オブジェクトの欠損値を他のオブジェクトの値で穴埋めすることができます。
#pandas.merge関数の例のためのデータフレーム
df1 = pd.DataFrame( {'key': list('bbacaab'), 'data1': list(range(7))}, columns=['key','data1'])
print( df1 )
df2 = pd.DataFrame( {'key': list('abd'), 'data2': list(range(3))}, columns=['key','data2'])
print( df2 )
#pandas.merge関数の使用例 --- 共通の列ラベルkeyを用いてマージ
pd.merge(df1, df2)
# keyの値が'c'と'd'がないことに注意。これはデフォルトの 'inner' joint モードの結果
pd.merge(df1, df2, how='outer')
# 今度はkeyの値が'c'と'd'がある。これが 'outer' joint モード
#pandas.concat関数の例のためのデータフレーム
df1 = pd.DataFrame( {'key': list('bbacaab'), 'data1': list(range(7))}, columns=['key','data1'])
print( df1 )
df2 = pd.DataFrame( {'key': list('abd'), 'data1': list(range(3))}, columns=['key','data1'])
print( df2 )
#pandas.concat関数の使用例 --- 行を「積み上げる」
pd.concat([df1,df2])
# 異なる列ラベルをもつデータフレームの場合
df1 = pd.DataFrame( {'key': list('bbacaab'), 'data1': list(range(7))}, columns=['key','data1'])
print( df1 )
df2 = pd.DataFrame( {'key': list('abd'), 'data2': list(range(3))}, columns=['key','data2'])
print( df2 )
pd.concat([df1,df2])
データの処理
データフレームに対して適用できる処理の基本について紹介します。import pandas as pd
data = {'city' : ['Kyoto', 'Nagoya', 'Osaka', 'Yokohama'], 'population':[1.5, 2.3, 2.7, 3.7],
'prefecture' :['Kyoto', 'Aichi','Osaka','Kanagawa']} # それぞれのキーは長さ4のリストを値とする
df1 = pd.DataFrame(data, index=[4,3,2,1]) # データフレームを作る
df1 # Notebookではデータフレームは表として表示される
ある要素が表ラベルや列ラベルに現れているかどうかは in を用いて調べられます。
print('city' in df1.columns) # 列ラベルの中に'city'があるか
print(4 in df1.index) # 行ラベルのチェック
ある要素がデータフレームに現れているかどうかは少し工夫がいります。これには部分データを取り出す処理が必要になります。
| プロパティ | 説明 | 用例(dfはデータフレーム) |
|---|---|---|
| at | 行ラベルと列ラベルによりスカラー値(1個の要素)を参照する。locより高速 | df.at[行ラベル,列ラベル] |
| iat | 行番号と列番号によりスカラー値(1個の要素)を参照する。ilocより高速 | df.iat[行番号,列番号] |
| loc | 行ラベルと列ラベルにより、ベクトル(複数の要素)もしくはスカラー値を参照する | df.loc[行ラベル,列ラベル] |
| iloc | 行番号と列番号により、ベクトル(複数の要素)もしくはスカラー値を参照する | df.iloc[行番号,列番号] |
| ix | locとして機能するが、ラベルが指定されていなければilocとして機能する | df.ix[行ラベル,列ラベル] |
df = pd.DataFrame(np.arange(12).reshape(3,4), columns=list('abcd'),index=list('xyz'))
df # Notebookではデータフレームは表として表示される
# 行ラベルと列ラベルを指定してスカラー値を参照
print( df.at['y','b'] )
print( df.loc['y','b'] )
print( df.ix['y','b'])
# 行ラベルのスライスと列ラベルを指定してベクトルを参照 --- atは使用できない
print( df.loc['x':'y', 'c']) # Pythonのスライスと異なり、「先頭:最後」を表す
print( df.ix['x':'y', 'c'])
# 行ラベルの範囲指定と列ラベルの範囲を指定して部分データフレームを参照 --- atは使用できない
print( df.loc['x':'y', 'b':'c']) # Pythonのスライスと異なり、「先頭:最後」を表す
df.ix['x':'y', 'b':'c']
# 行と列を複数指定して部分データフレームを参照
print(df.loc[['x','z'],['a','c']])
# 行番号と列番号を指定してスカラー値を参照
print( df.iat[0,2] ) # 0行2列目
print( df.iloc[0,2] )
print( df.ix[0,2])
# 行番号のスライスと列番号のスライスを指定して部分データフレームを参照 --- iatは使用できない
print( df.iloc[0:2, 1:3]) # 最初の2行、かつ2番目と3番目の列---Pythonのスライスと同じ意味になる
df.ix[0:2,1:3]
# 条件を指定して部分データフレームを取り出す(フィルタリング):df.c > 5を満たす行から最初の2列のデータを参照
df.ix[df.c > 5,:2]
基本的な演算処理
データフレームの四則演算は、演算記号 +-*/による方法と、メソッドを用いて行う方法があります。df1 = pd.DataFrame(np.arange(6).reshape(2,3), columns=list('abc'))
df2 = pd.DataFrame(np.arange(10,16).reshape(2,3), columns=list('abc'))
print(df1)
print(df2)
print(df1 + df2) # 加算
df3 = df1.add(df2)
print(df3)
print(df1 - df2)
df3 = df1.sub(df2)
print(df3)
print(df1 * df2)
df3 = df1.mul(df2)
print(df3)
print(df1 / df2)
df3 = df1.div(df2)
print(df3)
このように要素ごとの演算が行われます。またメソッドを使っても、もとのデータフレームの値は変化しません。 ですから、例えばdf1 + df2 の結果をdf1 の値としたい場合は、 df1 = df1.add(df2) のように書く必要があります。
比較演算
メソッドとして下の表に示す比較演算子が用意されています。比較結果は要素ごとに真理値(ブール値)であらわされます。NaNとの比較をしたり、ラベルが異なる場合はFalseが値になります。| メソッド | 説明 (df1.lt(df2)のように使った場合) |
|---|---|
| lt | df1 < df2 の要素ごとの比較結果を要素と留守データフレームを返す |
| gt | df1 > df2 の要素ごとの比較結果を要素と留守データフレームを返す |
| le | df1 <= df2 の要素ごとの比較結果を要素と留守データフレームを返す |
| ge | df1 >= df2 の要素ごとの比較結果を要素と留守データフレームを返す |
| eq | df1 == df2 の要素ごとの比較結果を要素と留守データフレームを返す |
| ne | df1≠ df2 の要素ごとの比較結果を要素と留守データフレームを返す |
df1 = pd.DataFrame(np.arange(6).reshape(2,3), columns=list('xyz'))
df2 = pd.DataFrame(np.arange(12).reshape(3,4), columns=list('xyza'))
print(df1,"\n", df2)
df1.lt(df2)
df2.gt(df1)
df1.le(df2)
df2.ge(df1)
df1.eq(df2)
df2.ne(df1)
関数の適用
データフレームなどのpandasのオブジェクトに特定の関数を適用するには、Numpyの関数を使う、pandasで用意されている関数やメソッドを使う、外部関数を適用するためのメソッドを使うという方法があります。ここでは外部関数、つまりPythonの一般の関数を適用する方法を紹介します。それには次の表のメソッドを使います。
大きく分けてベクトル(データフレームの列など)に関数を適用するメソッドと、一つ一つの要素に適用するメソッドがあります。ベクトルデータにはapplyを、一つ一つの要素にはmapまたはapplymapを用います。
| メソッド | 説明 |
|---|---|
| apply | シリーズやデータフレームの行や列に関数を適用 |
| map | シリーズ、データフレームの行や列の各要素に対して辞書変数や関数を用いて、結果を計算 |
| applymap | データフレームの各要素に作用する関数を適用 |
df = pd.DataFrame(np.arange(6).reshape(2,3), columns=list('xyz'),index=list('ab'))
df
df.apply(max) # 各列の最大値を計算
df.apply(min) # 各列の最小値を計算
df.apply(sum) # 各列の総和を計算
import numpy as np
df.apply(np.mean) # 各列の平均を計算
dic = {x:x*10 for x in range(6)}
print(dic) # 辞書を作成
df.y.map(dic) # df['y']にdicを適用 --- df.map(dic) は使えない
def func(x):
if (x % 2 == 0):
return 'even'
else:
return 'odd'
df.applymap(func)
プロット機能
PandasにはMatplotlibのサポートによって図を生成する機能があります。Matplotlibを使うのに比べ、簡便にできるのが特徴です。はじめにプロットを作成する例を示します。この例ではlineプロットとbarプロットを一つずつ作成しています、
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.random.randn(100,3), columns=list('xyz'), index=pd.date_range('1/1/2017',periods=100))
df1.head() # 作成したデータフレームの先頭の行を示す
df1 = df1.cumsum() # 累積和
df1.head() # 上の表と比べてどのように変化しているか?
%matplotlib inline
ax = df1.plot()
ax.set_ylabel('Value',fontsize=12) # 折れ線グラフ

df2 = pd.DataFrame(np.random.rand(5,3),columns=list('abc'))
df2
df2.plot(kind='bar',stacked=True) # bar形式の棒グラフ

df2.hist() # ヒストグラム

df2.plot(kind='box') # 箱ひげ図

ファイルの入出力
csvファイルの読み込み(入力)とcsv形式のファイルとして書き出し(出力)ができる。CSVファイルの読み込み
read_csv関数を用いれば、1行目をヘッダー(header)として認識する。ヘッダーがない場合はheader=Noneとしておくこと。この実習には、あらかじめSampleData.zipをダウンロードし、Intro2Pandas.ipynbと同じフォルダーに展開しておくこと。
import pandas as pd
df1 = pd.read_csv("SampleData/Example1.csv") # ヘッダーがあるcsvファイルの読み込み
df2 = pd.read_csv("SampleData/Example2.csv", header=None) # ヘッダーがないcsvファイルの読み込み
df3 = pd.read_csv( "SampleData/Example2.csv", names=('a', 'b', 'c') ) # ヘッダーがないファイルを読み込み、ヘッダーをつける
# いずれも行ラベルは勝手に 0,1,2,...とつけられる
dft = pd.read_csv("SampleData/ExampleT.csv", delimiter="\t") # 区切りがコンマではなくタブの場合
df1
df2
df3
dft
CSVファイルへの書き出し
to_csv関数により出力される。データフレームの形式(列ラベルも行ラベルもついたまま)で出力されるので、行ラベルを出力したくない場合はindex=Falseを指定すること。
また区切り記号をコンマではなくタブにするには、sep='\t'を指定する
df1.to_csv('Output1.csv' ) # 行ラベルあり
df1.to_csv('Output2.csv', index=False) # 行ラベル無し
df1.to_csv('OutputT.csv',sep='\t') # タブを区切り記号に
演習問題
この演習問題では、Fisherのiris(あやめ)のデータを用いる。まず以下を実行して、irisデータをロードし、pandas形式に変換し、変数dfの値とせよ。import matplotlib.pyplot as plt
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target_names[iris.target]
df.head()
以下の問題に解答せよ。
1. dfの中身を表示させないで、dfの行数、dfの列ラベル、dfのtarget列の値の種類(上の結果では、setosaだけが表示されている)をそれぞれ答えよ。
# 問題1
2. df.targetの値が'setosa'である行から、sepal lengthとpetal lengthの列だけをもつ部分データフレームを取り出し、変数setosaの値とせよ(フィルタリング)。
# 問題2
3.同様に、df.targetの値が'versicolor'である行から、sepal lengthとpetal lengthの列だけをもつ部分データフレームを取り出し、変数versicolorの値とせよ(フィルタリング)。
# 問題3
4. この2つのデータフレームを連結してひとつのデータフレームを作り、変数Xの値とせよ。
# 問題4
5. setosaのsepal lengthの列とpetal lengthの列データをそれぞれsetosa_sepal, setosa_petal変数の値とせよ。
# 問題5
6. 同様に、versicolorのsepal lengthの列とpetal lengthの列データをそれぞれversicolor_sepal, versicolor_petal変数の値とせよ。
# 問題6
7, 以下のコードを走らせ、散布図を表示せよ。そしてそれぞれのコードの意味を説明せよ。(注意: 前の2問の結果を使っている)
# plot data
plt.plot(setosa_sepal, setosa_petal,'ro', label='setosa',)
plt.plot(versicolor_sepal, versicolor_petal,'bx', label='versicolor')
plt.xlabel('petal length [cm]')
plt.ylabel('sepal length [cm]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()

# 問題7
8. irisデータにある3種類のアヤメに対し、問題7を参考にして、なるべく少ない手間でsepal lengthをx軸、petal lengthをy軸とした散布図を書け。次のような図が得られると良い。
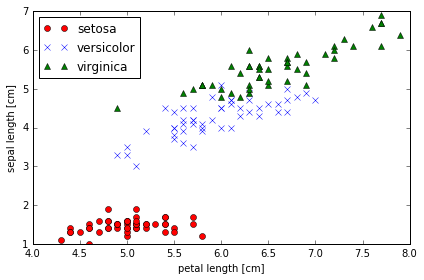
# 問題8
9. 以下の問いに答えよ。
- irisデータのすべてのデータに対し、sepal lengthの平均と標準偏差を求めよ。なお、平均は mean、標準偏差は std というインスタンス・メソッドで計算できる。
- irisデータのsepal lengthデータを取り出し、これを標準化せよ。ここで標準化とは平均が0, 分散が1となるようにデータを変換することをいう。
- 標準化したデータを用いて、問題8と同様に、sepal lengthをx軸、petal lengthをy軸とした散布図を書いてみよ。参考図は下:
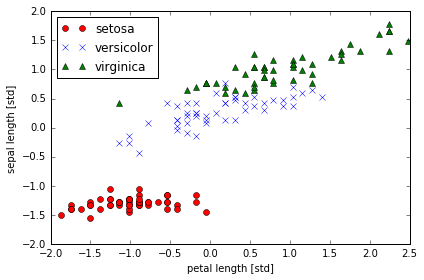
# 問題9