Rで統計学を学ぶ(4)
この講義では、教科書の第5章「統計的仮説検定」をとりあげます。
これは、統計的仮説検定の手順の理解と用語の習熟がねらいです。
また、代表的な統計的仮説検定、つまり標準正規分布を用いた検定、t分布を用いた検定、無相関検定、カイ二乗検定について学びます。
このウェブページと合わせて教科書を読み進めてください。
学習項目です:
下の散布図を見てください(青色の円は、点の分布の状態を表すために描いたものです):
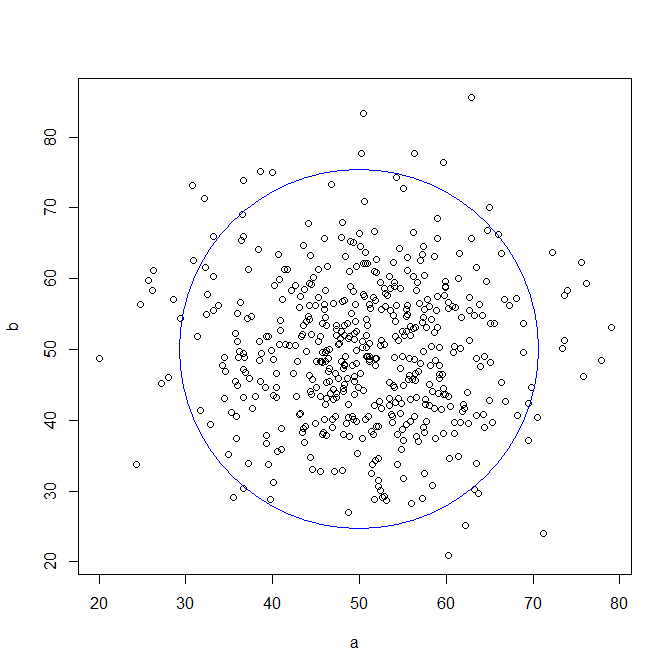
これをみると、この2つの変数 a と bの間には相関関係がないようにみえます。実際
cor(a,b)= -0.034なので相関なしといえます。
ところが、a, bそれぞれから30点ずつ無作為抽出したデータ xa, xb (下にその散布図を示す)は、
ときに 0.378 という『弱い相関』を示すことがあります。
[
無相関の母集団から相関するデータを作る]
次が無相関の母集団から相関するデータを作った方法です:
a <- rnorm(500)*10+50
b <- rnorm(500)*10+50
plot(a,b)
points(50, 50, cex=50, col="blue")
for (i in 1:100) {
xa <- sample(a, 30)
xb <- sample(b, 30)
if (abs(cor(xa, xb)) > 0.30) break
}
xx <- lm(xb ~ xa)
plot(xa, xb)
abline(xx, col="blue")
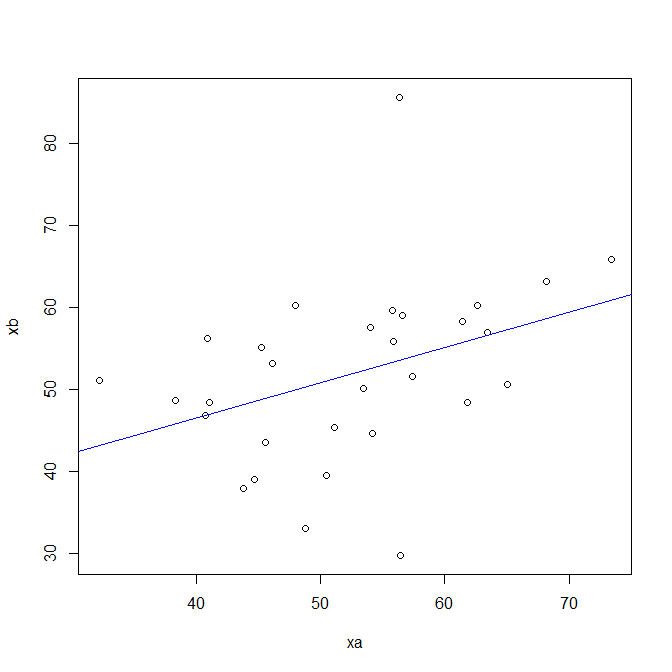
これは、実際には作為的に作られたデータです。しかし、あなたが発明した機器の有効性を示す論文や、あなたが作った薬品の効果を示す論文において、都合の良いデータだけを集めたのではないか、もしくは作為がないとしても、このデータは本当に偶然の結果であって多数のデータを取ればこのようなグラフにはならないのではないか、という疑いがかけられることがあります。
そのような疑いや批判には、(前の章で学んだように)『標本抽出が無作為抽出であること』(都合の良いデータを集めたわけではない)、そして(本章で学ぶように)『母集団に全く相関がないとしたら、抽出した標本からこのような結果が得られる可能性が非常に小さいということ』(多数のデータを集めても同じような結果が得られる確率が高い)を示さなければなりません。そして、
統計的仮説検定は確率に基づき、後者の主張を行うための方法です。(前者の「無作為抽出」は、統計による分析の大前提です)
統計的仮説検定の一般的な手順を次の表に示します:
| 手順 |
やること |
| 1 |
母集団に関する帰無仮説と対立仮説を設定
|
| 2 |
検定統計量を選択
|
| 3 |
有意水準 αの値を決定
|
| 4 |
データを収集した後、データから検定統計量の実現値を求める
|
| 5 |
結論: 検定統計量の実現値が棄却域に入れば帰無仮説を棄却し、対立仮説を採択する。そうでなければ、帰無仮説を採択する
|
1. 帰無仮説と対立仮説
- 帰無仮説:提案する手法が従来の手法と「差がない」、
提案する手法は「効果がない」という仮説---本来主張したいこととは逆の仮説。
この仮説が棄却されることを目標として仮説検定を行う。
具体的には、母平均μ=0 (母平均は0である), 母相関係数 ρ=0 (相関がない), 母平均の差μ1 - μ2= 0 (差がない)というような仮説
- 対立仮説: 帰無仮説が棄却されたときに採択される仮説---
帰無仮説とは逆の仮説であり、実験などで示したい・主張したいことを表したもの
具体的には、母平均μ≠0 (母平均は0でない), 母相関係数 ρ≠0 (相関がある), 母平均の差μ1 - μ2≠ 0 (差がある)というような仮説
対立仮説の設定により、検定は次のどちらかで行う(両側検定の方がより厳しい条件であり、
普通は両側検定で行う):
- 片側検定:対立仮説が、母平均μ > 0 (もしくはμ < 0 )、
、母相関係数 ρ > 0 (もしくはρ < 0 )、、母平均の差μ1 > μ2 (もしくはμ1 < μ2 )、の場合
- 両側検定:対立仮説が、母平均μ≠0、母相関係数ρ≠0 、母平均の差 μ1 - μ2≠ 0の場合
要するに、両側検定では、例えば母平均μ≠0を調べるには、母平均μ > 0 と μ < 0 の両方を調べなければならない
帰無仮説が正しいものとして分析を行う。
実際に得られたデータから計算された検定統計量の値によって採択を判断する。
帰無仮説が正しいとしたとき、検定統計量が、ほぼ起こり得ない値(それほど極端な値)であれば、帰無仮説を棄却する(つまり、本来の主張を表す対立仮説が採択される)。そうでなければ(確率的に十分起こりうるような値であれば、帰無仮説を採択する(この場合は、本来主張したかった対立仮説が棄却されてしまう)。
2. 検定統計量
- 検定統計量:統計的仮説検定のために用いられる標本統計量のこと。代表的な検定統計量の例: t, χ2、F
- 検定統計量の実現値:実際のデータ(手に入った標本)を基に計算してえられる具体的な値のこと
検定統計量の実現値は、
対立仮説に合うほど 0から離れた値を示す
3. 有意水準と棄却域
対立仮説を採択するか決定するときに基準になるのが
有意水準(αで表されます)
有意水準は
5%または1%(α=0.05またはα=0.01)に設定することが多い(つまり、標本が100回に5回(5%の場合)以下にしか現れないデータであった---こんなことは偶然では起こりえない---、だから帰無仮説が成り立たないと考えて良いのではないか、という判断基準)
帰無仮説が正しいものとして考えた時の標本分布を
帰無分布という---帰無分布に基づいて確率計算される
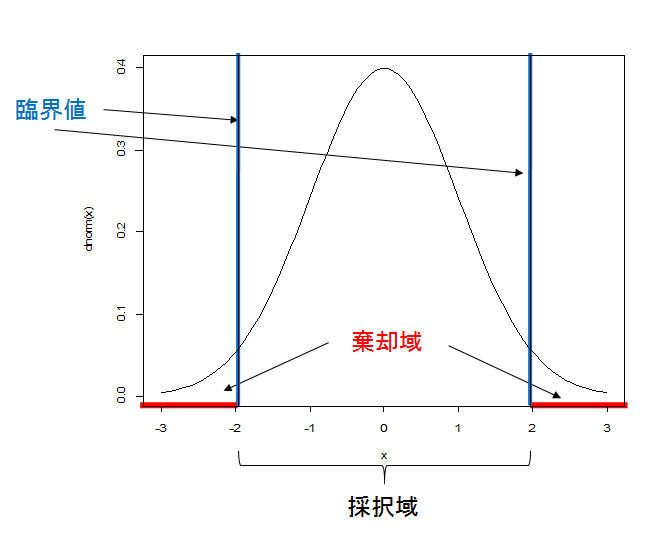
帰無仮説のもとで、非常に生じにくい検定統計量の値の範囲を
棄却域という---帰無仮説が棄却される領域(だから、この範囲に入るのが『望ましい』)
- 採択域: 棄却域以外の部分---「帰無仮説が採択される領域」
- 臨界値: 棄却域と採択域の境目の値
棄却域に検定統計量の実現値が入ったら、帰無仮説を棄却する---本来主張したかったことが採択される!
|
| 正規分布を帰無分布とした時の棄却域
|
4 & 5. 統計的仮説検定の結果の報告
検定統計量の実現値が棄却域に入った場合、「差がない」という帰無仮説を棄却し、
「差がある」という対立仮説を採択する。
検定結果は5% (または1%)水準で有意である
または
「p < .05 (または p < .01 )で有意差が見られた 」
と記述する。
帰無仮説が棄却できない場合は、「検定の結果、差が有意でなかった」または「有意差が認められなかった」と書く。
課題4-1
あなたはランダムに配置された対象物(例えば地雷や石油や埋蔵金など)を衛星からのセンサーデータを元に限定された時間(例えば1時間)内に検出する機器を作成した。100個のデータに対し検出率は0.70であった。そして、その性能が従来の製品(検出率は0.60と宣伝されている)よりも優れていることを統計的仮説検定の手法により示したい。
どのような帰無仮説と対立仮説をたてればよいか、また検定方法は片側か両側か、有意水準はどのくらいに設定したらよいか、考えを述べよ。
p値
p値:
帰無仮説が正しいという仮定のもとで、標本から計算した検定統計量の実現値以上の値が得られる確率
p値が有意水準より小さい時に帰無仮説を棄却する
[
p値が小さいことの意味]
p値の大きさが対立仮説を採択する(帰無仮説を棄却する)決め手となります。p値が小さいということは、
『帰無仮説が正しいとすると』確率的にほとんど起こりえないことが起きた(有意水準が5%なら100回中5回以下、
1%なら100回中1回以下)ということを意味します。逆にp値が大きいということは、確率的にはよくあることが起きた(だから、この結果では差があるとはいえない)、
ということになります。
第1種の誤りと第2種の誤り
- 第1種の誤り α: 「帰無仮説が真のとき、これを棄却してしまう」誤りのこと
この種の誤りを犯す確率が「有意水準」または「危険率」
- 第2種の誤り β:「帰無仮説が偽のとき、これを採択する(棄却できない)」誤りのこと
本当は差があるのに「差がない」と判断してしまう誤り
検定力
検定力:帰無仮説が偽の場合、全体の確率1から第2種の誤りの確率(1 - β)を引いた確率
「第2種の誤りを犯さない確率」とも、つまり間違っている帰無仮説を正しく棄却できる確率のこと
正規母集団
N (μ,σ
2) から無作為に標本を抽出する(サンプルサイズを n とする)と
標本平均の分布も正規分布
標本平均の平均は [ア] 、分散は [イ ] (問題:ア、イに当てはまる記号を書け---課題4-2)
これを標準化したものを
検定統計量とする(
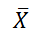
は標本データの平均):
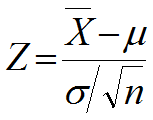
課題4-2
正規母集団
N (μ,σ
2) から無作為に標本を抽出したとき、
理論的に標本平均の平均と、分散がそれぞれどのように表されるか、書きなさい(つまり、上の[ア], [イ]の箇所を補うこと)。
またこれを標準化して得られる検定統計量がZで表されている理由を答えなさい。
[
ヒント]
標本分布を求めるの項(教科書では4.5.4節)を読みなおしてください。また、標準化については
標準化の項(教科書では2.10節)を見てください。
Rを使った実習(教科書pp.115-118)
例題:「心理学テスト」が
N (12, 10)の正規分布に従うものとする。
次のデータ(
「指導法データ」と呼ぶ)はこの母集団から無作為抽出した標本と考えてよいかどうかを判定せよ
指導法データ <- c(13,14,7,12,10,6,8,15,4,14,9,6,10,12,5,12,8,8,12,15)
次のステップで行う:
- 帰無仮説と対立仮説をたてる: 帰無仮説は「無作為抽出した標本と考えて良い」、つまりμ=12
対立仮説は「無作為抽出した標本ではない」、つまりμ≠12
- 検定統計量の選択: 標本データを標準化した値(Zで表す)
- 有意水準の決定: 両側検定で、有意水準 5%、つまりα=0.05
- 検定統計量の実現値の計算:
> z <- (mean(指導法データ) - 12) / sqrt(10/length(指導法データ))
> z
[1] -2.828427
- 帰無仮説の棄却か採択かの決定: 帰無仮説によればこの標本は正規分布に従う。そこでqnorm関数で棄却の臨界値を求める、
もしくはpnorm関数でp値を求める
- 下側確率:標準正規分布に従う確率変数Zを例にとると、Zがある値α以下となる確率 Prob(Z ≦ α)
- 上側確率:標準正規分布に従う確率変数Zを例にとると、Zがある値αより大きくなる確率 Prob(Z > α)
> qnorm(0.025)
[1] -1.959964
> qnorm(0.975)
[1] 1.959964
この結果、棄却域は Z < -1.959964 または Z > 1.959964となるので、Zの値は棄却域に入る。
よって、結論「有意水準5%において、指導法データは心理学テスト(という母集団)から無作為抽出した標本とはいえない」。
なお、関数pnormを用いて、直接p値を求めることもできる:
> pnorm(-2.828427)
[1] 0.002338868
> pnorm(2.828427, lower.tail=FALSE)
[1] 0.002338868
> 2*pnorm(-2.828427)
[1] 0.004677737
課題4-3
標準正規分布のグラフを書き、有意水準5%の棄却域を黄色で表し、例題のZ値がどこに位置するかを重ね書きした図を作成せよ。
[
ヒント]
前節
正規分布の「正規分布グラフに領域を表示する関数」で紹介した関数を拡張修正して用いる。
Z値以下の領域をオレンジ色で表すと次のような図が得られる:
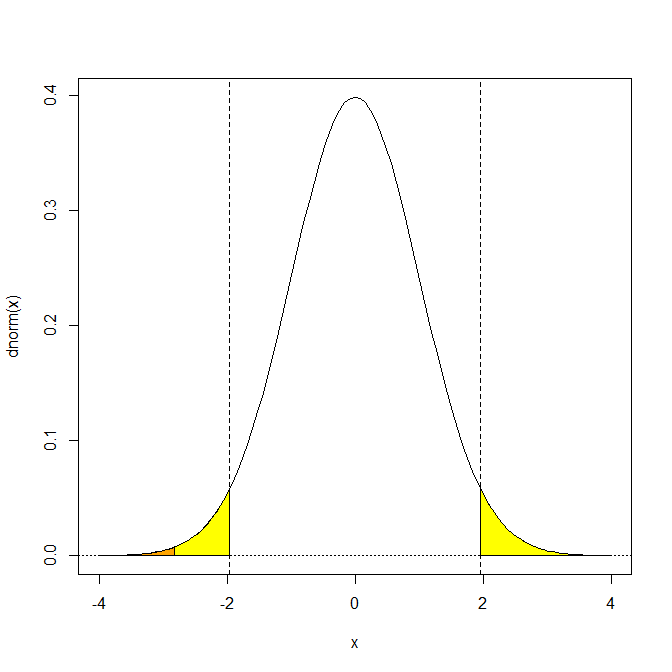
正規母集団からの無作為標本であっても、母集団の分散σ
2がわからない場合、
先の方法が使えません---先の検定で用いた検定統計量が計算できないからです
そこで母分散の平方根σ の代わりに、標本から求められる不偏分散の平方根
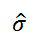
を使い、
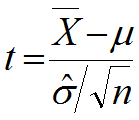
を検定統計量とする。
これは
自由度(df) n-1 の
t分布に従う
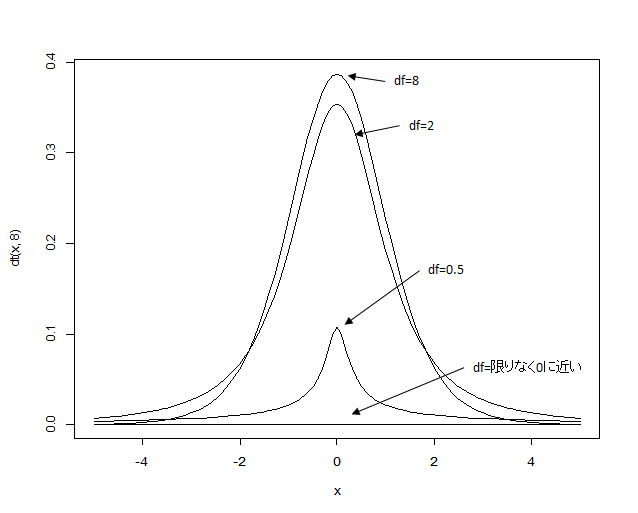
- t分布:統計学でよく利用される、正規分布の形に似た左右対称・山形の確率分布
- 自由度(df):t分布の形状を決める
Rを使った実習(教科書pp.120-123)
例題:「心理学テスト」が平均12の正規分布に従うものとする(
分散は未知!)。
前項にあげた「指導法データ」が、この母集団から無作為抽出した標本と考えてよいかどうかを判定せよ
次のステップで行う:
- 帰無仮説と対立仮説をたてる: 帰無仮説は「無作為抽出した標本と考えて良い」、つまりμ=12
対立仮説は「無作為抽出した標本ではない」、つまりμ≠12
- 検定統計量の選択: 標本の不偏分散の平方根を用い、
を検定統計量とする
- 有意水準の決定: 両側検定で、有意水準 5%、つまりα=0.05
- 検定統計量の実現値の計算:
> t <- (mean(指導法データ) - 12) / sqrt(var(指導法データ)/length(指導法データ))
> t
[1] -2.616648
- 帰無仮説の棄却か採択かの決定: 帰無仮説によればこの検定統計量は自由度df=n-1=19のt分布に従う
> qt(0.025,19)
[1] -2.093024
> qt(0.975,19)
[1] 2.093024
この結果、棄却域は t < -2.093024 または t > 2.093024となるので、tの値は棄却域に入る。
関数 pt を用いて、直接p値を求めることもできる:
> pt(-2.616648,19)
[1] 0.00848546
> pt(2.616648,19, lower.tail=FALSE)
[1] 0.00848546
> 2*pt(-2.616648,19)
[1] 0.01697092
よって、結論「有意水準5%において、指導法データは心理学テスト(という母集団)から無作為抽出した標本とはいえない」。
Rでt検定するための関数t.test:
> t.test(指導法データ, mu=12)
One Sample t-test
data: 指導法データ
t = -2.6166, df = 19, p-value = 0.01697
alternative hypothesis: true mean is not equal to 12
95 percent confidence interval:
8.400225 11.599775
sample estimates:
mean of x
10
無相関検定:「母集団において相関が0である」と設定して行う検定
母集団相関係数(母相関)に関する検定を行うときは、標本相関係数rから次を求めて検定統計量とする:
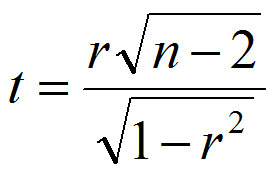
Rを使った実習(教科書pp.124-128)
例題:以下で与えられる「統計学テスト1」と「統計学テスト2」の得点の相関係数の検定を行え。有意水準は5%とする。
統計テスト1 <- c(6,10,6,10,5,3,5,9,3,3,11,6,11,9,7,5,8,7,7,9)
統計テスト2 <- c(10,13,8,15,8,6,9,10,7,3,18,14,18,11,12,5,7,12,7,7)
次のステップで行う:
- 帰無仮説と対立仮説をたてる: 帰無仮説はρ = 0、つまり母相関=0
対立仮説は「ρ≠ 0」、、つまり母相関≠0
- 検定統計量の選択:
- 有意水準の決定: 両側検定で、有意水準 5%、つまりα=0.05
- 検定統計量の実現値の計算:
> 標本相関 <- cor(統計テスト1,統計テスト2)
> 標本相関
[1] 0.749659 # 強い相関
> サンプルサイズ <- length(統計テスト1)
> t分子 <- 標本相関*sqrt(サンプルサイズ-2)
> t分母 <- sqrt(1-標本相関^2)
> t統計量 <- t分子/t分母
> t統計量
[1] 4.805707
- 帰無仮説の棄却か採択かの決定: 帰無仮説によればこの検定統計量は自由度df=n-2=18のt分布に従う
> qt(0.025,18)
[1] -2.100922
> qt(0.975,18)
[1] 2.100922
この結果、棄却域は t < -2.100922または t > 2.100922となるので、tの値は棄却域に入る。
よって結論「統計学テスト1と統計学テスト2は有意水準5%において強い相関(相関係数0.75)がある」。
関数 pt を用いて、直接p値を求めることもできる:
> pt(4.805707,18, lower.tail=FALSE)
[1] 7.08114e-05
> 2*pt(4.805707,18,lower.tail=FALSE)
[1] 0.0001416228
Rで無相関検定するための関数cor.test:
> cor.test(統計テスト1,統計テスト2)
One Sample t-test
Pearson's product-moment correlation
data: 統計テスト1 and 統計テスト2
t = 4.8057, df = 18, p-value = 0.0001416
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.4596086 0.8952048
sample estimates:
cor
0.749659
2つの質的変数が独立かどうかを確かめる---
独立とは「2つの質的変数に連関がない」こと
- 独立性の検定:2つの質的変数間の連関の有意性を調べる検定
- 期待度数:2つの変数の間に連関がない(独立である)という帰無仮説のもとで、帰無仮説が正しければ(連関がなければ)これくらいの度数をとるだろうと期待される度数
クロス集計表におけるセルの期待度数 = (セルが属する行の周辺度数 ×セルが属する列の周辺度数)÷総度数
- χ2(カイ2乗)という確率分布を利用するため、カイ自乗(2乗)検定ともいう。
- 独立性の検定における検定統計量の式
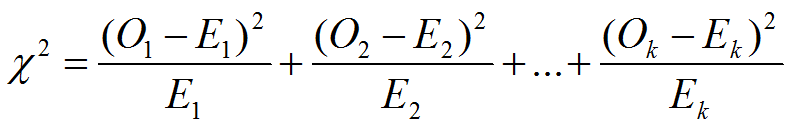
O1~Okは観測度数、E1~Ekは期待度数
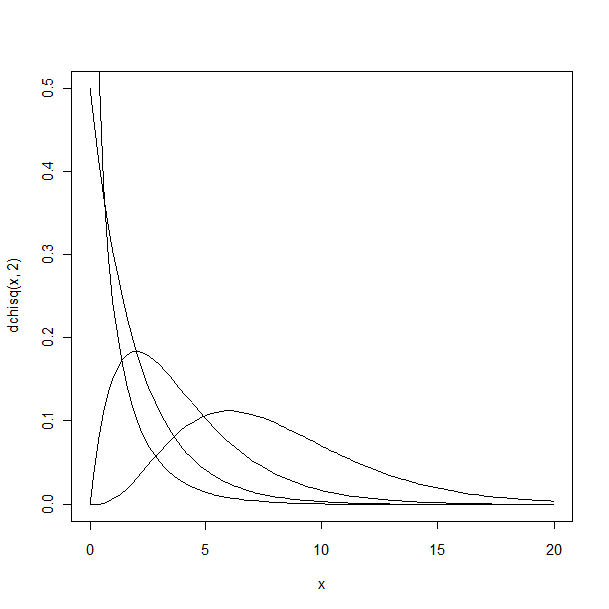
- カイ二乗分布:
Rを使った実習(教科書pp.128-135)
例題:20名の学生に対し数学と統計学の好き嫌いをアンケート調査した結果が以下。このことから、一般に数学と統計学の好き嫌いの間に有意な連関があるといえるかどうか、有意水準5%で検定せよ。
数学 <- c("嫌い","嫌い","好き","好き","嫌い","嫌い","嫌い","嫌い","嫌い","好き","好き",
"嫌い","好き","嫌い","嫌い","好き","嫌い","嫌い","嫌い","嫌い")
統計学 <- c("好き","好き","好き","好き","嫌い","嫌い","嫌い","嫌い","嫌い","嫌い","好き",
"好き","好き","嫌い","好き","嫌い","嫌い","嫌い","嫌い","嫌い")
このクロス集計表は以下:
| |
統計学嫌い |
統計学好き |
合計 |
| 数学嫌い | 期待度数イチイチ | 期待度数イチ二 | 14 |
| 数学好き | 期待度数二イチ | 期待度数二二 | 6 |
| 計 | 12 | 8 | 20 |
マスのことを
セル、セルに書かれた数値を
観測度数、
観測度数を各々、列・行で合計したものを
周辺度数、周辺度数の合計を
総度数と呼ぶ
自由度 df = (行の数-1)×(列の数-1)
次のステップで行う:
- 帰無仮説と対立仮説をたてる: 帰無仮説H0は、「数学と統計学の2つの変数は独立(連関なし)」
対立仮説H1は「「数学と統計学の2つの変数は独立(連関なし)」
- 検定統計量の選択:
- 有意水準の決定: 5%とする(片側検定---カイ二乗検定は棄却域が一つしかない)
- 検定統計量の実現値の計算:
> 期待度数イチイチ <-12*14/20
> 期待度数ニイチ <- 12*6/20
> 期待度数イチニ <- 8*14/20
> 期待度数ニニ <- 8*6/20
> 期待度数 <- c(期待度数イチイチ,期待度数ニイチ,期待度数イチニ,期待度数ニニ)
> 観測度数 <- c(10,2,4,4)
> カイ二乗要素 <- (観測度数 - 期待度数)^2/期待度数
> カイ二乗 <- sum(カイ二乗要素)
> カイ二乗
[1] 2.539683
- 帰無仮説の棄却か採択かの決定: 帰無仮説によればこの検定統計量は自由度df=1のχ2分布に従う
> qchisq(0.95,1)
[1] 3.841459
> qchisq(0.05,1,lower.tail=FALSE)
[1] 3.841459
この結果、棄却域は χ2> 3.84 となるので、この例題におけるχ2の値は棄却域に入っていない、つまり帰無仮説は棄却されず、採択される。
よって結論「有意水準5%において、数学と統計学の2つの変数は独立ではない(連関がない)」。
関数 pchisq を用いて、直接p値を求めることもできる:
> pchisq(2.539683, 1, lower.tail=FALSE)
[1] 0.1110171
Rでカイ二乗検定するための関数chisq.test:
> クロス集計表 <- table(数学, 統計学)
> chisq.test(クロス集計表, correct=FALSE)
Pearson's Chi-squared test
data: クロス集計表
X-squared = 2.5397, df = 1, p-value = 0.111
警告メッセージ:
In chisq.test(クロス集計表, correct = FALSE) :
カイ自乗近似は不正確かもしれません
標本における連関の大きさが全く同じであっても、サンプルサイズが異なると検定の結果が変わることがある
サンプルサイズが大きくなると、有意になりやすい---統計的仮説検定一般にいえる性質
> 履修A <- matrix(c(16,12,4,8),2,2)
> rownames(履修A) <- c("文系","理系")
> colnames(履修A) <- c("履修した","履修しない")
> 履修A
履修した 履修しない
文系 16 4
理系 12 8
> chisq.test(履修A,correct=F)
Pearson's Chi-squared test
data: 履修A
X-squared = 1.9048, df = 1, p-value = 0.1675
> 履修B <- matrix(c(160,120,40,80),2,2)
> rownames(履修B) <- c("文系","理系")
> colnames(履修B) <- c("履修した","履修しない")
> 履修B
履修した 履修しない
文系 160 40
理系 120 80
> chisq.test(履修B,correct=F)
Pearson's Chi-squared test
data: 履修B
X-squared = 19.0476, df = 1, p-value = 1.275e-05
| 目的 |
関数名と書式 |
使い方 |
| 正規分布の確率密度関数 |
dnorm(x,mean,sd)
| dnorm(0,mean=0,sd=1)
⇒ 標準正規分布におけるx=0のときの確率密度
|
| 標準正規分布で下側確率に対応する値を求める |
qnorm(p) |
qnorm(0.025) ⇒ Prob(Z < q) = 0.025となるqの値。上側確率を求めるときは、lower.tail=FALSEとする |
| 標準正規分布で下側確率を求める |
pnorm(q) |
pnorm(1.96) ⇒ Prob(Z < 1.96)の値。上側確率を求めるときは、lower.tail=FALSEとする |
| t分布の確率密度関数 |
dt(x,df)
| dt(1,19)
⇒ 自由度19のt分布でx=1のときの確率密度
|
| t分布で下側確率に対応する値を求める |
qt(p, df) |
qt(0.025, 19) ⇒ 自由度19のt分布で下側確率0.025となるtの値。
上側確率を求めるときは、lower.tail=FALSEとする |
| t分布で下側確率を求める |
pt(q,df) |
pt(2.62, 19) ⇒ 自由度19のt分布で下側確率Prob(t < 2.62)を計算。
上側確率を求めるときは、lower.tail=FALSEとする |
| t検定を行う |
t.test(x,mu) |
t.test(心理学テスト, mu=12) ⇒ 心理学テストの得点について、
帰無仮説: μ=12の検定を行う |
| 無相関検定を行う |
cor.test(x,y) |
cor.test(数学テスト, 物理学テスト) ⇒ 数学テストと物理学テストの母相関の検定を行う。method=の値に"spearman"または"kendall"を指定することで、順位相関係数についての検定ができる
|
| カイ二乗分布の確率密度関数 |
dchisq(x,df)
| dchisq(3.841,1)
⇒ 自由度1のカイ二乗分布でx=3.841のときの確率密度
|
| カイ二乗分布で下側確率に対応する値を求める |
qchisq(p,df) |
qchisq(0.95, 1)⇒ 自由度1のカイ二乗分布で P(0 < χ2< q)=0.95となるqを求める。
上側確率を求めるときは、lower.tail=FALSEとする |
| カイ二乗分布で下側確率を求める |
pchisq(q,df) |
pchisq(3.5, 1)⇒ 自由度1のカイ二乗分布で P(0 < χ2< 3.5)の確率を求める。
上側確率を求めるときは、lower.tail=FALSEとする |
| カイ二乗検定を行う |
chisq.test(クロス集計表) |
chisq.test(クロス集計表) ⇒ カイ二乗検定を行う。
table関数で作成したクロス集計表の結果を引数とする。デフォルトでは連続性の補正が行われるので、補正なしにしたい場合はcorrect=FALSEを指定する
|
| 図に直線を追加する |
abline() |
abline(v=1.96) ⇒ カイ二乗検定を行う。
⇒ x軸(横軸)に垂直な直線x=1.96を図に追加する。
abline(h=3.0)でx軸に水平な直線y=3.0を、
abline(a=2.0,b=1.0)でy=bx+a (=1.0x+2.0)を追加する。
|
教科書 p.139 問題(1)
次のデータ(単位はcm)は、平均170cmの正規分布に従う20歳男性の母集団からの無作為抽出と考えてよいかどうかを、
t.test関数を用いて検定せよ。
身長 <- c(165,150,170,168,159,170,167,178,155,159,161,162,166,171,155,160,168,172,155,167)
教科書 p.139 問題(2)
以下に示す第3章練習問題(1)のデータにおいて、勉強時間と定期試験の成績の相関係数の無相関検定を行え。
勉強時間 <- c(1, 3, 10, 12, 6, 3, 8, 4, 1, 5)
定期試験 <- c(20, 40, 100, 80, 50, 50, 70, 50, 10, 60)
教科書 p.139 問題(3)
先の問題(2)のデータに対し、スピアマンの順位相関係数、およびケンドールの順位相関係数を求め、
さらに無相関検定をせよ。
[
スピアマンの順位相関係数とケンドールの順位相関係数]
教科書p.127の説明にあるように、
cor.testにおいて、デフォルトであるピアソンの積率相関係数以外に、
次のものが求められます;
- スピアマンの順位相関係数を求めるには: method="spearman" を指定
- ケンドールの順位相関係数を求めるには: method="kendall" を指定
教科書 p.139 問題(4)
以下に示す第3章練習問題(3)のデータに対し、カイ二乗検定を行え。
洋食派か和食派か <- c("洋食","和食","和食","洋食","和食","洋食","洋食","和食","洋食","洋食",
"和食","洋食","和食","洋食","和食","和食","洋食","洋食","和食","和食")
甘党か辛党か <- c("甘党","辛党","甘党","甘党","辛党","辛党","辛党","辛党","甘党","甘党","甘党","甘党",
"辛党","辛党","甘党","辛党","辛党","甘党","辛党","辛党")
教科書 p.139 問題(5)
次のそれぞれのデータについて無相関検定を行え。
(5-1)のデータ:
国語 <- c(60,40,30,70,55)
社会 <- c(80,25,35,70,50)
(5-2)のデータ --- 単純に(5-1)のデータを2回繰り返したもの
国語 <- c(60,40,30,70,55,60,40,30,70,55)
社会 <- c(80,25,35,70,50,80,25,35,70,50)
問題(6)
badmington.csvは区切り記号がコンマのCSVのファイルであり、
バドミントンのラケットの重量xと硬度yの表(出典: 内田(2010)「すぐに使えるRによる統計解析とグラフの応用」東京図書)が収められている。このデータをデータフレームとして読み込み、硬度(y)と重量(x)の相関係数を算出し、無相関の検定を行え。
[
csvファイルを読み込む]
区切り記号がコンマのcsvファイルを読み込み、その内容をデータフレームとして取り込むには、
read.csv関数を用いる。
Rで統計学(3) トップページに戻る Rで統計学(5)