Rで確率を学ぶ
これは、長畑(2009)『Rで学ぶ統計学』共立出版に基づく解説です。
学習項目です
- 事象: サイコロを一回振って6の目が出るというように起こる事柄
- 全事象: 起こりうる事象全体、Uで表す。サイコロの場合、1の目が出る、2の目が出る、3の目が出る、4の目が出る、5の目が出る、6の目がでる、という事象
- 和事象: 事象AとBの和事象A∪B とは、事象Aまたは事象Bのいずれかが起こる、という「事象」。サイコロの場合、2回サイコロを振ってどちらかで1の目が出るという事象は、「1回めに1の目がでる」事象と「2回めに1の目がでる」事象の和事象
- 積事象: 事象AとBの積事象A∩B とは、事象Aまたは事象Bのどちらもが起こる、という「事象」。サイコロの場合、2回サイコロを振ってどちらも1の目が出るという事象は、「1回めに1の目がでる」事象と「2回めに1の目がでる」事象の積事象
- 余事象: 「事象Aが起こらない」という事象¬Aを、事象Aの余事象という。サイコロの場合、「1の目が出る」の余事象は、「1の目が出ない」、つまり全事象から「1の目が出る」事象を除いたものとなる
- 排反: 事象AとBが互いに同時に起こりえないとき、事象Aと事象Bが排反である、という。またこれを A∩B = φ で表す。
事象に基づいて
確率が定義される。事象(仮にAで表す)が起こる確からしさの程度を0から1の間の数値で表したものを
事象Aの(起こる)確率 P(A) とし、次の性質を満たすものとする:
確率の公理
- どの事象Aについても、0 ≦ P(A) ≦ 1
- 全事象Uに対し、 P(U)=1
- 互いに排反な事象A1, A2,…, Anに対し、事象A1, A2,…, Anのいずれかが起こる和事象
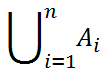 に対し、以下が成り立つ:
に対し、以下が成り立つ:
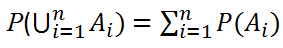
これから次の性質が導かれる:
- P(A∪B) = P(A) + P(B) - p(A∩B)
- P(¬A) = 1 - P(A)
- 事象Aのもとでの事象Bの条件付き確率 P(B|A): 事象Aが起こった(もしくは事象Aが起こっているという情報がある)という条件のもとで事象Bが起こる確率
(参考: 最近、高校の数学にも取り入れられた。高校生向けの解説は例えば旺文社の条件付き確率の解説がある)
P(A∩B) = P(A)P(B | A) = P(B) P(A|B)
が成り立つ
注意: この式はいつも成り立つ。これと対照的に(間違って覚えている人が多い) P(A∩B) = P(A)P(B) は一般には成り立たない。言い換えれば、一般には P(A|B) ≠ P(A), P(B|A) ≠ P(B)である。
- 事象Aと事象Bが独立: 事象Aが起きても起きなくても事象Bが起こる確率に変わりがないとき(その逆も)。このときは、P(A|B) = P(A), P(B|A) = P(B) が成り立つので、P(A∩B) = P(A)P(B) となる
演習問題1-1
(頭の準備のための問題)
6面体のサイコロにおいて、インチキでないサイコロでは1の目がでる確率が1/6であることを示しなさい。また、そのサイコロを2回振って最初の出目をx, 二回目の出目をy としたとき、x+y=6となる確率を求めなさい。
演習問題1-2
乱数を用いて、通常の6面体のサイコロにおいて、1の目がでる確率が1/6となるかどうか、確かめてみよう。
サイコロを600回、6000回、60000回、600000回ふったときに1の目がでる回数を乱数を用いてシミュレーションし、それぞれで1の目がでる確率が1/6に近いかどうかを調べてみよう。
[
ヒント]
一様乱数を発生させる関数は第1回目の演習で紹介した
runifを使う。
これを使って、次のようにすれば、100回のサイコロ振りをシミュレーションできる。
x <- floor(runif(100,1,7))
この結果、xには1,2,3,4,5,6のいずれかの数、合計100個の数を要素とするベクトルが値になる。そこで、1の目の出現回数は次のようにして求められる:
length(x[x==1])
もしくは、次のようなコードを書いても良いだろう: (nの値は適宜変える)
sim <- function(n=100) {
x <- floor(runif(n,1,7))
for(y in 1:6) {
cat(y,"=>\t",length(x[x==y]),"\t",length(x[x==y])/n, "\n")
}
}
演習問題1-3
事象AとBに対し、次の式が成り立つことを示せ:
P(B | A) = P(B) P(A|B) / P(A)
[
ヒント]
事象AとBの積事象が成り立つ確率について述べた次の式を使う:
P(A∩B) = P(A)P(B | A) = P(B) P(A|B)
演習問題1-4
形状も重さも同じである赤球と白玉がそれぞれ50個ずつある箱から目をつぶって一個取り出してそれが赤球である確率はいくらか。
次に、赤球を10個だけ入れた箱を3箱、赤球10個と白球10個を入れた箱を1箱、赤球10個と白球40個を入れた箱を1箱、合計5箱用意したとする。
そして、まず目をつぶって箱を選び、そこから目をつぶって玉を一個取り出し、それが赤球であった場合の確率を求めよ。そして、
先の操作での答と値が違うことを確認せよ。
最初の操作と次の操作では共に赤球と白玉は50個ずつであったが、どうして2回の操作で確率が異なるのか、説明せよ。
- 全確率の定理:
互いに排反な事象 E1, E2,…, En(すなわち、i≠jであるすべてのi,j (1 ≤ i,j ≤ n)に対し、
Ei∩Ej=φ、E1∪ E2∪…∪En=U )と、任意の事象Aに対して次式が成立する:
P(A) = P(E1)P(A | E1) + P(E2)P(A | E2) + … + P(En)P(A | En) =
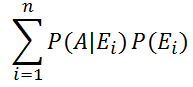
- ベイズの定理(Bayes theorem)
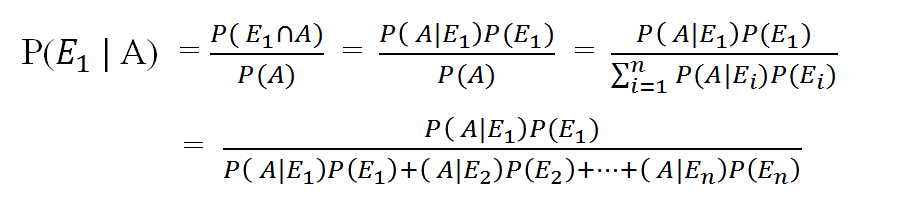
- 事前確率(prior probability, 無条件確率): P(E1), P(E2), … : 事象Aが観測される前(事前)に与えられているため、事前確率という
- 事後確率(posterior probability): P(E1|A), P(E2|A), … (条件付き確率): 事象Aが起こった後(事後)の確率であることから
演習問題2-1
ある病気に罹患しているかどうか検査において、「(ある人が)陽性反応が出る」という事象をAとし、「(その人が)実際に罹患しえいる」という事象をEとする。
そして、確率が次のように与えられているとする: P(A|E)=0.56, P(A|¬E) = 0.04, P(E)=0.035
この時、検査で陽性反応である確率と、陽性反応が出た時に実際に病気を発病する確率をそれぞれ求めよ。
[
ヒント]
求める確率は、P(A) と P(E|A) 。全確率の定理から P(A) = P(A|E)P(E) + P(A|¬E)P(¬E)。
またベイズの定理から、P(E|A)= P(A|E) P(E) / P(A) である。
なお、仮定から、P(¬A|E)=0.44,P(¬A|¬E)=0.96, P(¬E)=0.965 である。
演習問題2-2
とある適性検査で、(ある人が)適性と判定される事象をTとし、(その人が)実際に適性があるという事象をEとする。P(E)=0.60, P(T|E)=0.80, P(T|¬E)=0.040のとき、
ある人が適性と判定され、かつ実際に適性である事象の確率を求めよ。
[
ヒント]
求めたいのは、「適性と判定される」事象と、「実際に適性である」事象の積事象である。つまりP(T∩E)を求める。
演習問題2-3
三種類の物体(仮にA,B,C とする) の認識ができるカメラ機構を備えているロボットがある。
ロボットは、Aの物体を認識した場合には赤色のLEDを、Bの物体を認識した場合は緑色のLED を、C の物体を認識したら青のLED を点滅させる。
ただし、ロボットのカメラ機構は故障することがあり、故障した場合もロボットは赤色のLEDを点滅させる。
そして故障する事前確率は
p = 0.01 である。
ここで3 種類の物体の中から
N 個をランダムに選び、次々にロボットに提示した。すると、すべてロボットは赤色のLED を点滅させた。
N = 1の場合、
N=2の場合、…
N=10の場合、それぞれの場合に対し、ロボットのカメラ機構が壊れている確率を求めよ。
[
ヒント]
ロボットのセンサーが壊れているという事象をR,
i個目の物体を提示したときに赤色のLEDが点滅する事象をL
iとする。
すると、問題文から、(その他に情報がない場合の確率は「事前」確率): P(R)=0.01
これにより、ロボットのセンサーが壊れていない(事前)確率P(¬R)は1-P(R)=0.99となる。
ここで、
P(Li|R)の意味を考えると、
「ロボットのセンサーが壊れている」という状況のもとで「i番目の赤色LEDが
点滅するという(事後)確率であり、これは常に1である。また
P(Li|¬R)の意味を考えると、
「ロボットのセンサーが壊れて
いない」という状況のもとで
「i番目の赤色LEDが点滅するという(事後)確率であり、
これは各
Liが独立事象なら、その値は1/3である。
これらを前提として問題を解く。
N=1 の場合: このとき赤色のLEDが点滅した(という情報がある)のだから、
P(R|L1)が求めるべき(「赤色のLEDが点滅した」という情報が得られた後の確率なので、「事後」)確率である。
ベイズ則から,
P(R|L1)=P(L1| R)P(R)/P(L1)、
また全確率の定理から、
P(L1) = P(L | R)P(R) +P(L1|¬R)P(¬R)
である。よって、0.029 (有効数字2桁)となる。
N=2のときは、
L1, L2という二つの事象を考えると、
求めるべきものは
P(R|L1∩L2)である。
ベイズ則より、
P(R|L1∩L2)=P(L1∩L2|R)P(R)/P(L1∩L2)
ここで、
P(L1∩L2)の値は
また全確率の定理を用いて
P(L1∩L2|R)P(R) +
P(L1∩L2|¬R)P(¬R)により求められる。
それ以外の Nの値の場合については、以上の考えを適用してば答えることができる。
- 確率変数(random variable): 実数の値を取る変数Xの値が確率に基づくとき、Xを確率変数という。
そして、実際に取る値のことを実現値という
例: サイコロを投げて出る目を表す変数は確率変数で、その実現値は1,2,3,4,5,6の六通りある。
- 離散(計数)型確率変数: サイコロの目のように飛び飛びの値をとる確率変数
- 連続(計量)型確率変数: 身長や体重のように連続した値を取る確率変数
- 確率分布: (離散型)確率変数の実現値をx1, x2,…,xn、
それぞれの確率をp1, p2,…,pnとすると、{pi, i=1,…n}を確率分布という
- 分布関数 F(x): 確率変数Xの実現値がx以下である確率が以下のように書かれるときのF(x)
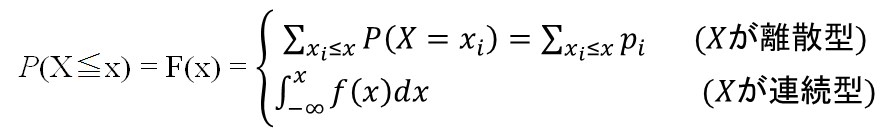
特にXが離散型の場合 P(X=xi)=pi を確率関数(p.f., probability function)、
Xが連続型の場合(分布関数の定義に現れる) f(x)を(確率)密度関数(p.d.f., probability density function)という
[
連続型確率変数の実現値と確率について]
『サイコロを振って出た目』を確率変数とみなすと、サイコロを振って出た目は1,2,3,4,5,6という飛び飛びの『実現値』を取る(例えば、3.5という値にはならない)ので、これは離散型確率変数と言われる。
それに対し、人の体重や身長を確率変数とみなすと、体重の場合0kgから300kgの間の値、身長なら0cmから300cmの間の値(連続した値)をとるので連続型確率変数と言って、離散型確率変数とは別の扱いになる。
ここで、離散型確率変数の場合、確率変数をX、その実現値をx
iで表すと、確率関数はp(X=x
i)と書ける。ところが、連続型確率変数の場合、確率変数をX、その実現値をx
iで表すとしても、確率関数はp(X=x
i)とは書けない。このことについて腑に落ちない人のためにここで説明する。
身長を確率変数とみなそう。するとクラスには実現値170cmの者がいるだろう。50人のクラスで10人がそうだとすれば「適当にクラスから人を選んでその身長が170cmである確率は10/50 = 0.20 」と言いたくなるかもしれない。しかしこれは次のような誤解と混同がある。
まず「誰かの身長がちょうど170cm」という値をとる確率はほとんど0である、という事実を指摘しておこう。なぜなら、170cmという値はどこかで『丸め』を行って得られた値だからである。計測器がcm刻みであったか、mm(ミリメートル)刻みであったか、μm(マイクロメートル)刻みか、nn(ナノメートル)刻みか、。。。ということを考えれば、cm刻みなら170cmということはありそうだが、nn刻みの場合、170cmちょうどいう値が得られるのはほとんど可能性がない、ということは容易に理解できよう。
つまり、我々が日常的に使っている「身長が170cmちょうど」というのは実は(例えば)169.5cmから170.5cmの範囲にある」ことの言い換えになっているのである。連続的に値を取る身長に対して確率のようなものを与える関数を確率密度関数(f(x)で表す)といい、連続型の確率変数の場合、ある値の幅の区間で定積分したもの(つまり、確率変数の実現値がある幅の値の範囲に入る可能性)が確率となるのである。ちなみに先の例でいえば、f(x)を区間[169.5, 170.5]の間で定積分した値が0.20 となる。
なお、身長をcm刻みで表示することにすれば、飛び飛びの値を取ることになり、この場合は「離散型確率変数」として扱われる。
分布関数と確率関数(密度関数)をグラフに書くと:
| 上段: 確率関数、下段:分布関数 |
上段: 密度関数, 下段: 分布関数 |
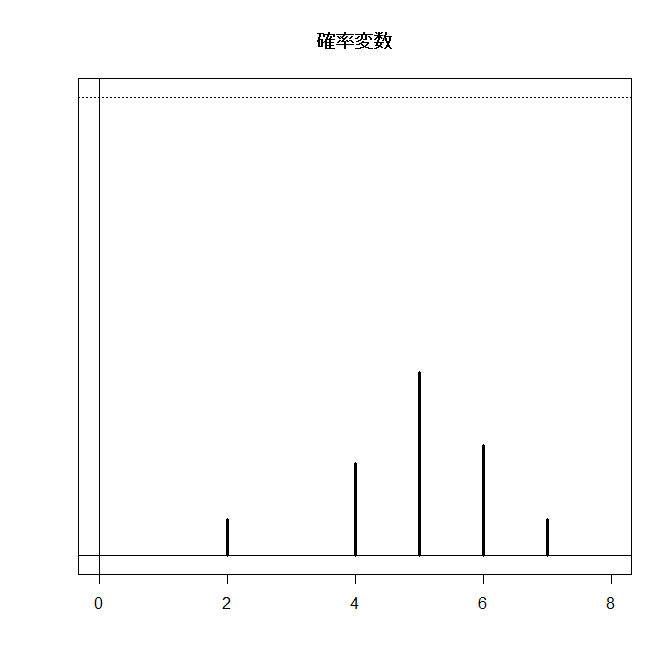 |
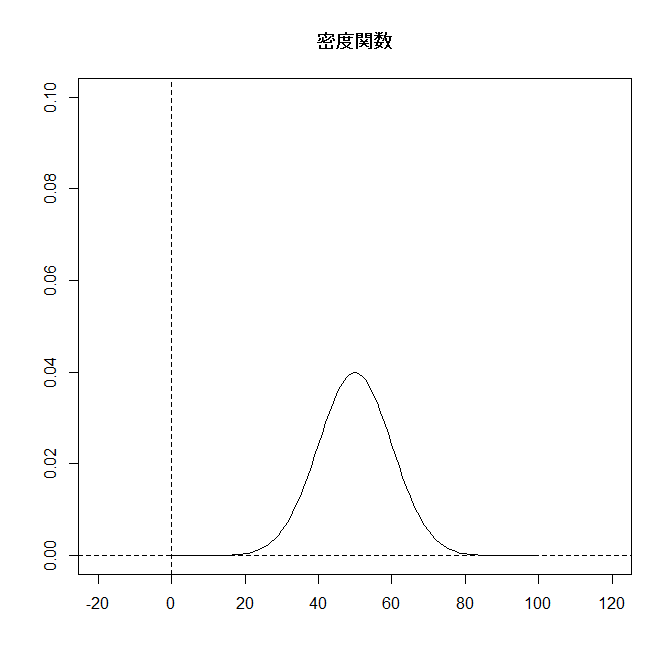 |
 |
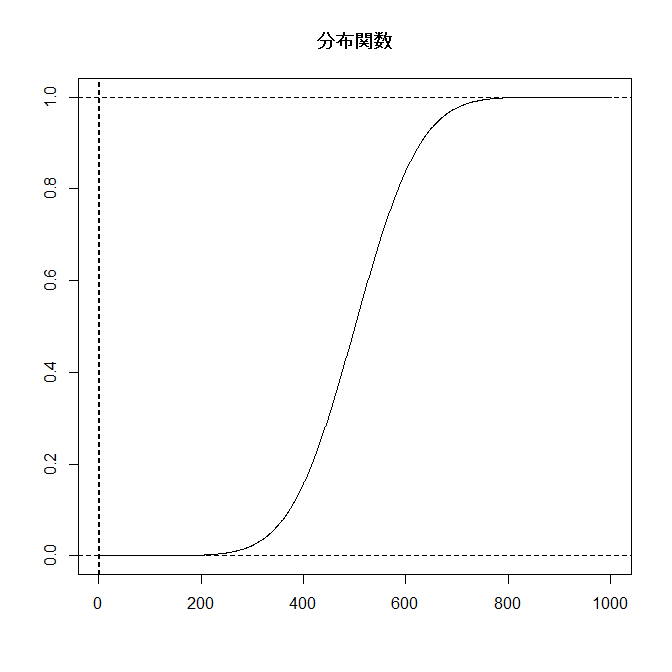 |
- 分布関数について次が成り立つ
| (1) F(x)は単調非減少 |
(2) 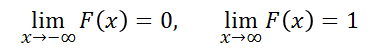 |
(3) F(x)は右連続な関数: 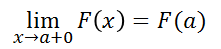
|
- 確率関数(密度関数)について次が成り立つ
| (1) pxi≥ 0 (f(x) ≥ 0) |
(2) 
|
演習問題3-1
裏表のあるコイン2枚を投げたときに、表の出る枚数の確率関数と分布関数を求めよ。ただし表か裏のどちらかになるものとする。
[
ヒント]
裏表のあるコイン2枚を投げたとき、表が出る枚数を確率変数Xとする。
Xの実現値は0, 1, 2 の3通りであり、離散型の確率変数である。
確率関数
P(X=
x)において、
x≠0,1,2の場合は
P(X=
x=0 は明らか。
そこで、
P(X=0),
P(X=1),
P(X=2)の値を求めれば良い。
例えばP(X=0)の値は、二枚とも裏の場合の確率なので、
1/2 * 1/2 = 1/4 = 0.25 と求められる。
分布関数は、P(X < 0)、P(X ≤ 0)、P(X < 1)、
P(X ≤ 1), P(X < 2)、P(X ≤ 2), P
(X < ∞) を求めれば良い。明らかに
P(X < 0) = 0,
P(X < 2) = P(X ≤ 2), P(X < ∞)
= 1.0である。
演習問題3-2
関数
f(
x )を、
0 <
x または π <
x のとき
f(
x ) = 0
0 ≤
x ≤ π のとき
f(
x) = (1/2)*sin(
x) とする。
問1.
f(
x )が確率関数の性質(1)と(2)を満たすことを示せ。
問2.
f(
x )を確率関数としたときの分布関数を表示せよ。
[
ヒント]
確率関数の性質(1)とは、0 ≤
f(
x )
性質(2)は、区間[-∞ , +∞] における
f(
x )の(定)積分が 1 になることである。
どちらも示すのは容易であろう。
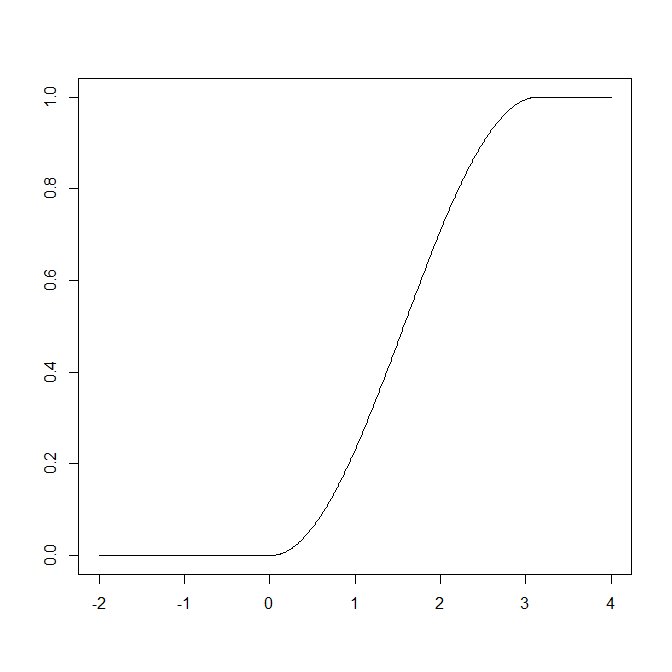
分布関数
F(
x )は、0 <
x のとき
F(
x)=0、
0 ≤
x ≤ π のときは、区間 [0,
x] における
f(
x)の定積分と等しく、
π <
x のときは
F(
x)=1である。これを表示すれば良い。
なお、この表示には、ベクトルに関数を適用した結果をベクトルにするsapply関数を使った: (分布関数をF(x)とすると、 x <- seq(-2,4,0.01); y <- sapply(x,F) ; plot(x,y,type="l")
確率変数Xが分布F(x)に従う確率変数であることを、X ~ F(x)と表す
- 期待値E(X): 確率変数 X の取る値とその確率の積の総和。(算術)平均、もしくは加重平均ともいう
(注:
「平均」にはこれ以外に幾何平均や調和平均などがあるが、これらは期待値(=算術平均)とは別のもの)式で書くと以下:
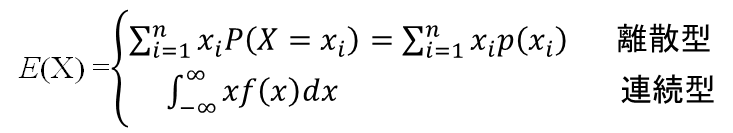
- 分散V(X): 確率変数Xの取る値と期待
値との差の二乗の総和の期待値。式で表すと
E((X - E(X))2)
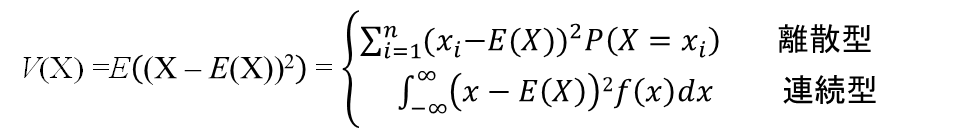
| 期待値の性質: | a, bを定数とすると、 E(aX + b) = aE(X)+b |
| 分散の性質: | V(X) = E(X2) - {E(X)}2 |
| | V(aX + b) = a2 V(X) |
- Xの原点周りのk次モーメント:
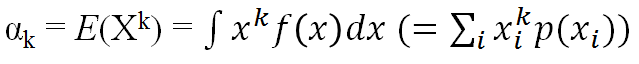
- Xの平均μ周りのk次モーメント:
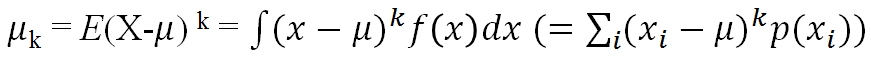
- Xの積率母関数: φ(θ) = E[eθX]
演習問題4-1
期待値の性質の式:
a, bを定数とすると、
E(aX + b) = aE(X)+b
が成り立つことを示せ。(ヒント: 積分の式から求める)
演習問題4-2
分散の性質の式
a, bを定数とすると、
V(X) = E(X2) - {E(X)}2、および V(aX + b) = a2V(X)
が成り立つことを示せ。(ヒント: 積分の式から求める。
また、E(X)が定数であることを用いる)
データは連続的な値を取る連続型分布と、とびとびの値をとる離散型確率変数に対応した確率分布の離散型分布とに分類される
確率分布の性質(グラフの形など)は「パラメタ」によって変わる。
そして関数率分布それぞれ、異なるパラメタを取る。
以下ではどのような関数率分布がどのようなパラメタを取るかにも注意してみよう。
連続型分布
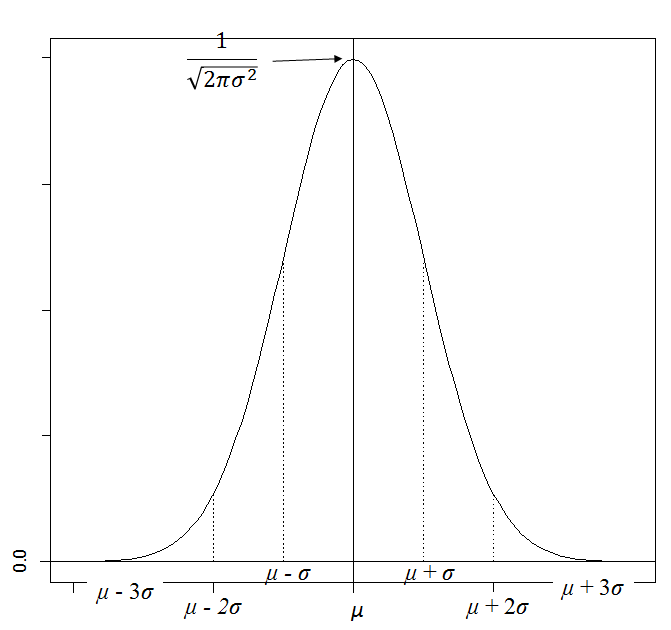 確率統計においてもっとも重要な確率分布である。一般にかなりの人数を対象とした試験の成績をx軸、その得点の人数をy軸に取ると、この分布に近いグラフが得られる。それだけではなく、ロボットの位置推定(カルマンフィルタなど)にも用いられている(ただし、この場合は多変数の正規分布になる)。また、正規分布に従うとは限らない確率変数でも、その実現値をグループごとの平均をとれば、そのグループの個数が多ければ多いほどその平均値は正規分布する(中心極限定理)。
確率統計においてもっとも重要な確率分布である。一般にかなりの人数を対象とした試験の成績をx軸、その得点の人数をy軸に取ると、この分布に近いグラフが得られる。それだけではなく、ロボットの位置推定(カルマンフィルタなど)にも用いられている(ただし、この場合は多変数の正規分布になる)。また、正規分布に従うとは限らない確率変数でも、その実現値をグループごとの平均をとれば、そのグループの個数が多ければ多いほどその平均値は正規分布する(中心極限定理)。
正規分布(normal distribution): 密度関数f(x)が以下の式で与えられる分布を、
平均μ、分散σ2の正規分布(またはガウス分布)といい、N (μ,σ2)で表す:
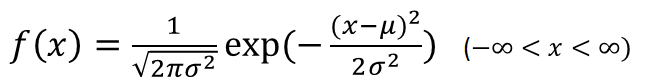
特にμ=0, σ=1の正規分布 (N (0, 1)) を標準正規分布という
参考: 区間[-∞, ∞]におけるf(x)の積分の値は1、
区間[μ-σ, μ+σ]におけるf(x)の積分の値は約0.683、
区間[μ-2σ, μ+2σ]におけるf(x)の積分の値は約0.954、
区間[μ-3σ, μ+3σ]におけるf(x)の積分の値は約0.997
正規分布の性質: X ~
N (μ,σ
2) のとき、E(X) = μ, V(X) = σ
2
- 中心極限定理:X1,…, Xnが互いに独立で、平均がいずれもμ、分散がσ2のとき(ここで、確率変数Xiは正規分布に従う必要はない)、データ数が増えてくるとその算術平均
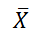 の分布は平均μ、分散σ2/nの正規分布で近似される
の分布は平均μ、分散σ2/nの正規分布で近似される
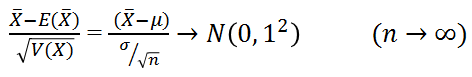
- X~N(μ,σ2)のとき、Y=aX+b(ここでa, bは定数)とすると、
演習問題4-1,および4-2から
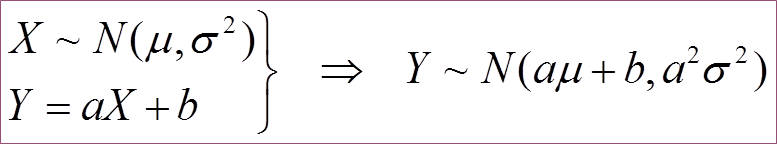
- X1~N(μ1,σ12)、
X2~N(μ2,σ22)、かつX1とX2が独立のとき、次が成り立つ:
a1X1+a2X2 ~ N(a1μ1+a2μ2,
(a1σ1)2+ (a2σ2)2)
参考: 正規分布の密度関数の描画:
curve(dnorm,-4,4,main="正規分布の分布関数",xlab="",ylab="")
abline(h=0,v=0,lty=1)
segments(2,0,2,0.054, lty=3)
segments(-2,0,-2,0.054, lty=3)
segments(-1,0,-1,0.24, lty=3)
segments(1,0,1,0.24, lty=3)
[
多変数の正規分布]
下に示される多変数の正規分布(ガウス分布)も重要である(
xと
μはd次元ベクトル、Σはd×dの行列(共分散行列), dは正整数)。
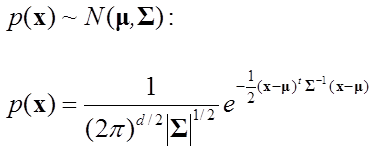
そして、次のような性質を持つ:
- n次元ベクトルX が N(μ,Σ)
に従うとする。また、
A がm×nの行列、b がm次元ベクトルとすると、
Y = AX + b は
N(Aμ + b, AΣATX) に従う
(ここで ATはA の転置行列)
その応用としては、例えば、ロボットの位置推定がある。
ロボットに例えば1m移動させようとしても、正確に1m移動することは不可能であり、1m移動した後の位置はその地点を平均とした正規分布に従うと考えられる。このような移動を繰り返していくと、位置はどんどん不確定になるが、そうであっても、ロボットの位置は正規分布で表すことができる。ここでセンサー(例えばGPS)によりロボットの位置についての何らかの情報が得られるとしよう。センサーで得られる情報はやはり誤差を含んだものである(車のナビを使っていて、道路を走っていても、ナビでは道路を外れたところを表示していることがしばしばある)。このセンサー情報も正規分布で表すことができる。
カルマンフィルタはロボットの移動の情報とセンサーの情報により、確率に基づいて、ロボットの位置推定を行うための優れた手法の一つである。
演習問題4-3
ここにロボットがある。このロボットは、1.0mの直進前進命令によって移動させると、
元の位置との相対距離はN(1.0, 0.01)に従うことがわかっている。
ここで、そのロボットは初め原点(x=0)におり、そこから1.0mの直進前進命令を2回出した。移動後のロボットの位置の確率分布はどのように表されるか。また、原点から2.0±0.0141 mの範囲にいる確率を求めよ。
演習問題4-4 (やらなくてもよいが、チャレンジした方にはポイント?)
正規分布に基づく乱数発生の関数が1章の演習問題で紹介したrnorm
であることを用いて、演習問題4-3の
「原点から2.0±0.0141 mの範囲にいる確率」をシミュレーションにより確かめてみよ。
(連続)一様分布
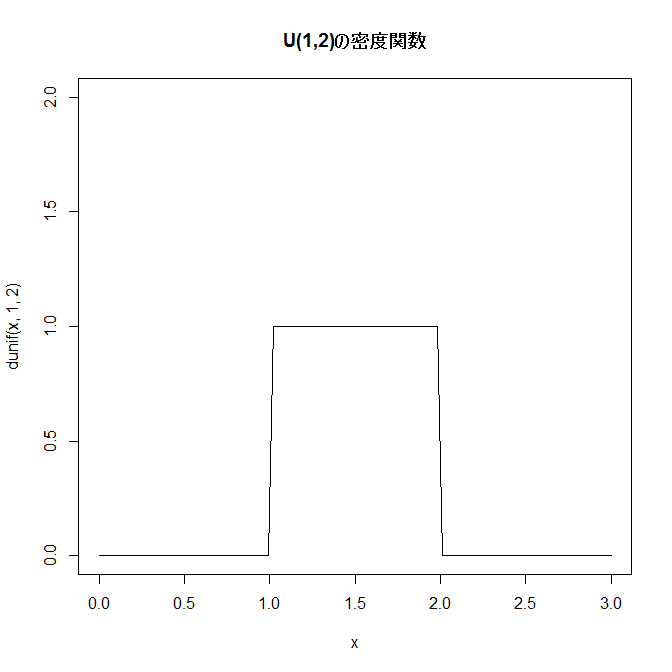 コンピュータで発生される(一様)乱数の分布がこの例である。また、ルーレットを回して止まったときの、ルーレットがどのくらい回転したかという分布(ただし0から2πまでの範囲とする)も一様分布とみなせる。
コンピュータで発生される(一様)乱数の分布がこの例である。また、ルーレットを回して止まったときの、ルーレットがどのくらい回転したかという分布(ただし0から2πまでの範囲とする)も一様分布とみなせる。
一様分布(uniform distribution): U(a,b)で表される。密度関数f(x)が次式で与えられる分布で、一様乱数が従う分布。a=1, b=2の場合の密度関数f(x)は右図:
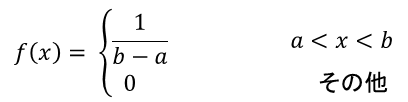
参考: 一様分布の密度関数の描画:
ccurve(dunif(x,1,2), xlim=c(0,3), ylim=c(0,2), main="U(1,2)の密度関数")
指数分布
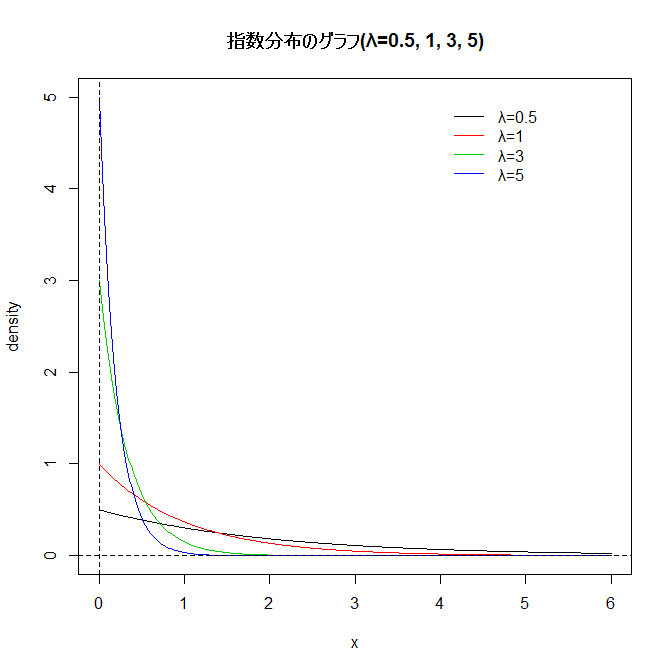 一様乱数で発生させた2つの数の距離は指数分布にしたがう。このように何らかの「事象」の発生間隔は一般に指数分布となる。
一様乱数で発生させた2つの数の距離は指数分布にしたがう。このように何らかの「事象」の発生間隔は一般に指数分布となる。
指数分布(exponential distribution): Exp(λ)で表す。密度関数f(x)が次式で与えられる分布で、
いくつかのλに対しf(x)は右図のようになる。待ち行列でよく利用される分布。
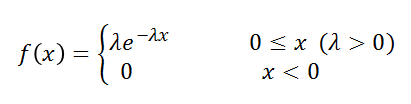
参考: 指数分布の密度関数の描画:
x <- seq(0,6,length=500)
u <- c(0.5, 1, 3,5)
y <- sapply(u, function(a) { a*exp(-a*x)})
matplot(x,y,type="l", lty=1, col=1:4, ylab="density",
main="指数分布のグラフ(λ=0.5, 1, 3, 5)")
legend(4,5,paste("λ=",u,sep=""),col=1:4, lty=1, bty="n")
abline(h=0, v=0, lty=2)
離散型分布
二項分布
 n枚のコインを投げてx枚が表になる確率は二項分布に従う。
n枚のコインを投げてx枚が表になる確率は二項分布に従う。
二項分布(binominal distribution): B(n, p) で表される、ここでn, pの意味は例で示す:
「不良率p (0 < p < 1) の工程からランダムにn個の製品をとったとき、そのうちのx個が不良品である確率は次式で与えられ、
この確率変数Xは二項分布B(n,p)に従う(X ~ B(n,p)):
P(X = x) = nCx px(1-p)n-x (x=0,1,…, n)
参考: 二項分布の確率関数の描画:
x=0:10
p<-seq(0.1, 0.9, 0.1)
y <- sapply(p,function(a){dbnom(x,10,a)})
y <- sapply(p,function(a){dbinom(x,10,a)})
matplot(x,y,type="o",lty=1,ylim=c(0,1),pch=1:9,col=1:9,ylab="density",
main="二項分布")
legend(2,1.1,paste("p=",p,"(n=10)",sep=""),col=1:9,lty=1,bty="n")
abline(h=0,v=0,lty=2,col=2)
ポアソン分布
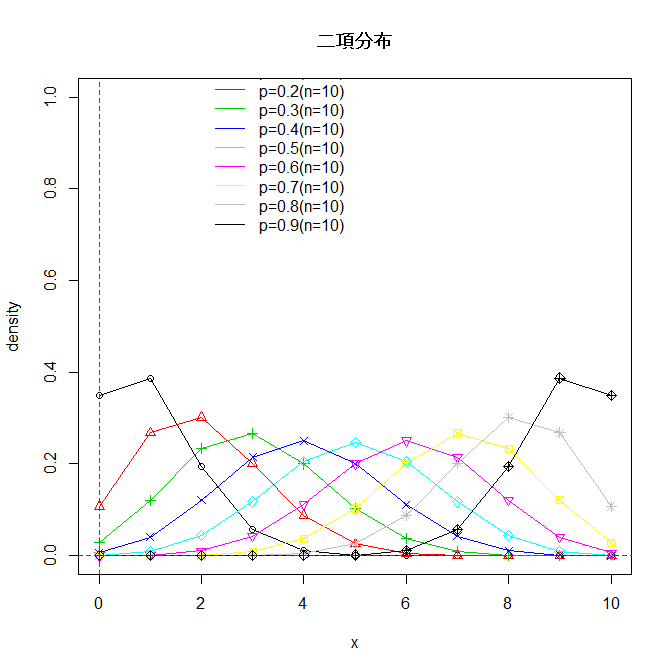
 あるエレベータに乗ろうとする人の1時間あたりの人数や、国道1km辺りのコンビニの数がポアソン分布と関連する確率変数です。
あるエレベータに乗ろうとする人の1時間あたりの人数や、国道1km辺りのコンビニの数がポアソン分布と関連する確率変数です。
ポアソン分布(Poisson distribution): Po(λ)で表される。ここでλは平均。
「1時間あたりに来店する客の数の平均をλ人であるとき、単位あたりの来客数Xがxである確率は次式で与えられ、Xは平均λのポアソン分布に従う(X ~ Po(λ)): P(X=x) = px = e-λλx / x! (x=0,1,…)
参考: ポアソン分布の確率関数の描画:
x <- 0:15
lam <- c(0.5, 1,2,3,4,5,7)
y <- matrix(0,nrow=16, ncol=7)
for(j in 1:7) { d<-dpois(x,lam[j])
y[,j] <- d
}
matplot(x,y,type="o",lty=1,ylim=c(0,0.7),pch=1:7,col=1:7,ylab="density",
main="ポアソン分布")
legend(6,0.7,paste("λ=",lam,sep=""),col=1:7,lty=1,bty="n")
abline(h=0,v=0,lty=2,col=1)
統計量の分布
カイ二乗(カイ自乗, カイ2乗、χ2)分布
統計的仮説検定でよく用いられる。
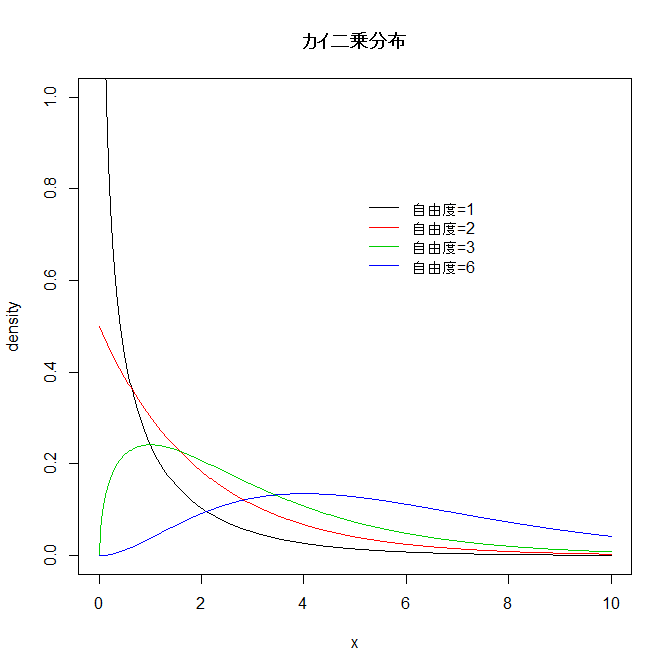
χ2分布(Chi square distribution) χ2n :
X1,…, Xnが互いに独立に標準正規分布N (0,12)に従うとき、
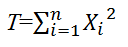 は自由度nの
カイ二乗分布に従うといい、T~χ2n と表す。
は自由度nの
カイ二乗分布に従うといい、T~χ2n と表す。
自然数nに対し、Tの密度関数は次で与えられる:
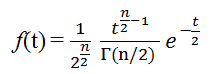
なお、Γ(x)はガンマ関数で、その定義は: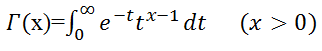
参考: カイ二乗分布の密度関数の描画:
x <- seq(0,10,length=500)
n <- c(1,2,3,6)
y <- sapply(n/2, function(a) { dgamma(x,shape=a,scale=2)})
matplot(x,y,type="l",ylim=c(0,1),lty=1,col=1:4,ylab="density",
main="カイ二乗分布")
legend(5,0.8,paste("自由度=",n,sep=""),col=1:4,lty=1,bty="n")
abline(h=0,v=0,lty=3)
(スチューデントの)t分布
正規分布する母集団の平均と分散が未知で標本サイズが小さい場合に平均を推定したり、2つの群の平均値の差の統計的有意性を示すのに利用される。
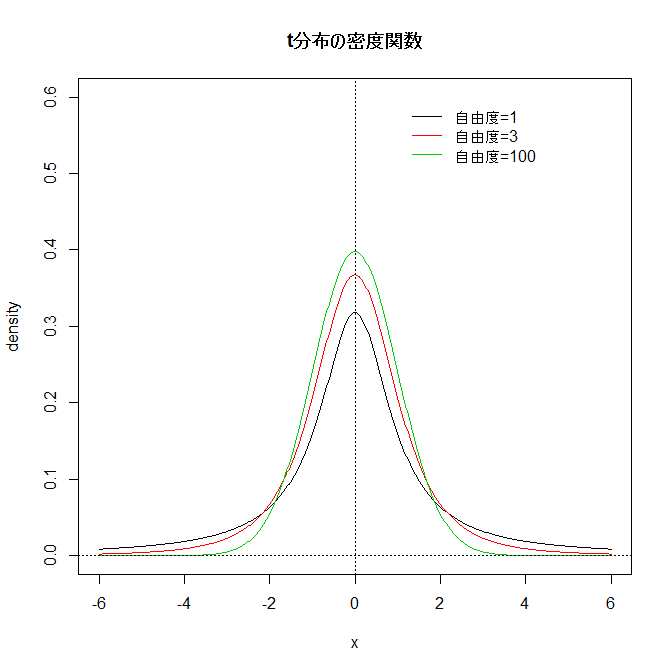
t分布(Student t distribution): Xが標準正規分布 N (0,12)に従い、それと独立なYが自由度nのカイ二乗分布に従うとき、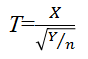 は自由度nの
t分布に従うといい、T~tn と表す。
は自由度nの
t分布に従うといい、T~tn と表す。
自然数nに対し、Tの密度関数は次で与えられる:
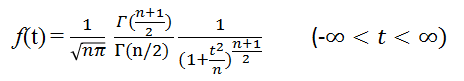
参考: t分布の密度関数の描画:
x <- seq(-6,6,length=500)
n <- c(1,3,100)
y <- sapply(n,function(a) { dt(x,a)})
matplot(x,y,type="l",ylim=c(0,0.6),lty=1,col=1:3,ylab="density",
main="t分布の密度関数")
legend(1,0.6,paste("自由度=",n,sep=""),col=1:3, lty=1,bty="n")
abline(h=0,v=0,lty=3)
F分布
上の2つの分布と並んで、推測統計や不確かさを論じる上で重要な分布です。
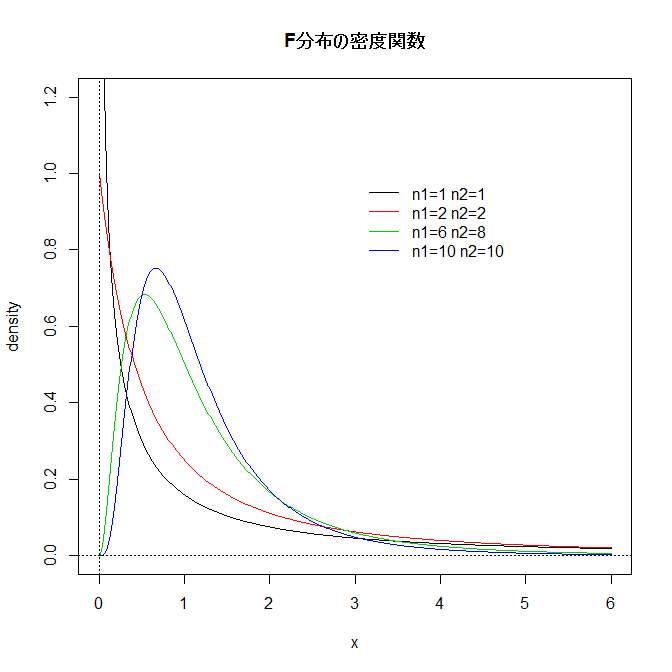
F分布(F distribution): Xが自由度mのカイ二乗分布に従い、それと独立なYが自由度nのカイ二乗分布に従うとき、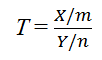 は自由度(m,n)のF分布に従うといい、T ~ Fm,nと表す。
は自由度(m,n)のF分布に従うといい、T ~ Fm,nと表す。
自然数m, nに対してTの密度関数は次で与えられる:
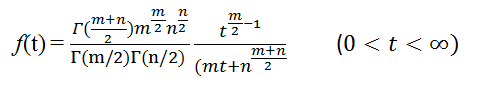
参考: F分布の密度関数の描画:
x <- seq(0,6,length=500)
y <- matrix(0, 500,4)
n1 <- c(1,2,6,10)
n2 <- c(1,2,8,10)
for(j in 1:4) {
d <- df(x,n1[j],n2[j])
y[,j] <- d
}
matplot(x,y,type="l",ylim=c(0,1.2),lty=1,col=1:4, ylab="density",
main="F分布の密度関数")
legend(3,1,paste("n1=",n1," n2=",n2,sep=""),col=1:4,lty=1,bty="n")
abline(h=0,v=0,lty=3)
演習5.
ここの解説に従い、いろいろな確率分布の密度関数を描画させてみよ。
Rの解説(4) トップページに戻る Rで統計学(1)