- 因子分析: 観測変数とよばれる複数の変数の値が与えられているとする。その観測変数(のいくつか)に共通して影響する要因(これを因子という)があると仮定し、少ない個数の因子によって、複数の観測変数の関係を説明しようとする。
[成績データ例の作成方法について]
教科書p.300の成績データは、p.308にある次のコードにより生成されます:
set.seed(9999)
n <- 200
因子負荷行列 <- matrix(c(0.09884, 0.17545, 0.52720, 0.73462, 0.45620, 0.72141, 0.47258,
0.17901, 0.07984, 0.37204), nrow=5)
独自性 <- diag(sqrt(c(0.530201, 0.254119, 0.309986, 0.546036, 0.346539)))
因子得点 <- matrix(rnorm(2*n),nrow=2)
独自因子 <- matrix(rnorm(5*n),nrow=5)
五教科 <- round(t(因子負荷行列 %*% 因子得点 + 独自性%*%独自因子)*10+50)
colnames(五教科) <- c("国語","社会","数学","理科","英語")
> 相関行列 <- cor(五教科)
> 相関行列
国語 社会 数学 理科 英語
国語 1.0000000 0.5500166 0.1953799 0.1630274 0.4275140 # 国語と社会の相関係数が0.55と高い
社会 0.5500166 1.0000000 0.3317530 0.2944938 0.5178159
数学 0.1953799 0.3317530 1.0000000 0.5301135 0.4575891 # 数学と理科の相関係数が0.53と高い
理科 0.1630274 0.2944938 0.5301135 1.0000000 0.3876493
英語 0.4275140 0.5178159 0.4575891 0.3876493 1.0000000 # 英語は他の教科との相関係数が0.39~0.52と全般的に高い
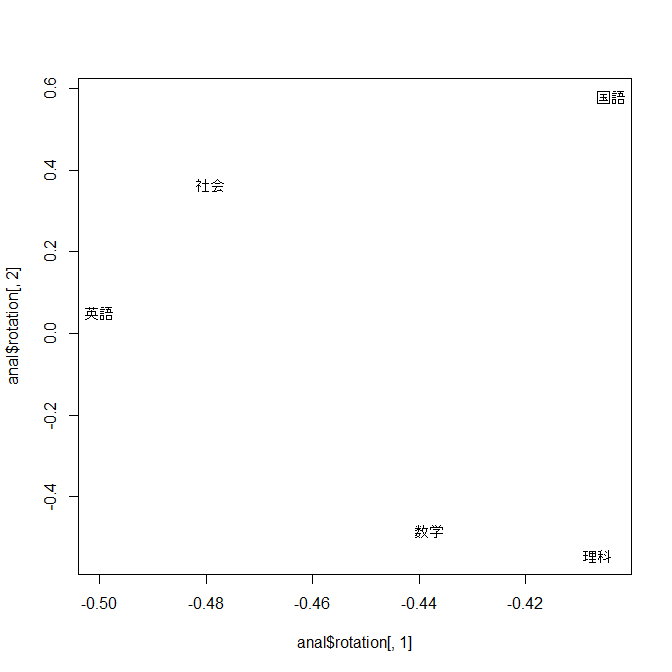
相関行列を求めてみると、国語と社会、数学と理科の相関係数が高いことがわかる(英語はどれとも相関する)。これにより文系、理系という因子の仮定は、それほど間違いではなさそう。。。そこで、因子の数を2(理系因子と文系因子)として因子分析を行う。
(因子分析を実際に使う場面では、因子の数をいろいろ変えてみて、最も妥当な解釈(説明)が可能な因子数を採用します)[因子の数を決める手がかり: 固有値]
固有値を参考にして因子数を決めるのもよい方法です。
Rではeigen関数を用いて簡単に固有値と固有ベクトルを求められます:
そういう見方からeigen(相関行列) の結果を見ると
1以上の固有値は2個なので、この例では因子数を2としたと言えます。
> eigen(相関行列)
$values
[1] 2.5573782 1.0656034 0.5058941 0.4461472 0.4249772
$vectors
[,1] [,2] [,3] [,4] [,5]
[1,] -0.4040025 0.57915506 -0.3526733 -0.30988872 0.53004894
[2,] -0.4791362 0.36314955 -0.1046695 0.07323541 -0.78881668
[3,] -0.4380493 -0.48395278 0.2494573 -0.71311577 -0.05603054
[4,] -0.4064807 -0.54402387 -0.6062633 0.39786745 0.11383232
[5,] -0.5000967 0.05029462 0.6594556 0.48142803 0.28411115
ここで values が固有値、
vectorsがそれぞれの固有値に対する固有ベクトルです。
ちなみに、そうであることは次の計算から確かめられます:
(Rでは一次元ベクトルは一行で表示されます)
> result <- eigen(相関行列)
> (相関行列 %*% result$vectors[,1])[,1]
国語 社会 数学 理科 英語
-1.033187 -1.225333 -1.120258 -1.039525 -1.278936
> result$values[1] * result$vectors[,1]
[1] -1.033187 -1.225333 -1.120258 -1.039525 -1.278936
> (相関行列 %*% result$vectors[,2])[,1]
国語 社会 数学 理科 英語
0.61714961 0.38697340 -0.51570173 -0.57971368 0.05359412
> result$values[2] * result$vectors[,2]
[1] 0.61714961 0.38697340 -0.51570173 -0.57971368 0.05359412
ところで、固有ベクトルとか固有値とはどういう意味でしたでしょうか。
定義は線形代数の講義を思い出してもらうとして、
固有ベクトルと固有値についてここでの重要なポイントは次のことです:
行列Aの固有ベクトルをx、固有値をλとし、 行列Aをベクトルxに作用させる(行列の意味で掛け算する)とは、 幾何的には、ベクトルxに対し線形変換(拡大縮小や回転) を施していているとみなせるつまり、固有ベクトルとは、行列Aを作用しても向きが変わらないもの、といえます。 因子分析の『文脈に即して言えば』、 行列Aを特徴づける成分の一つがxであるとみなせます。 また固有値は行列Aを作用した時の拡大率になりますが、 因子分析の『文脈に即して言えば』、 固有ベクトルxが行列Aを特徴づける成分での割合を表すものとみなせます。
そういう見方から
> 五教科因子分析 <- factanal(五教科, factors=2)
> 五教科因子分析
Call:
factanal(x = 五教科, factors = 2) # factanalが因子分析の関数、factorsの値が因子の数
Uniquenesses: # 独自性
国語 社会 数学 理科 英語
0.471 0.395 0.379 0.548 0.491
Loadings: # 因子負荷
Factor1 Factor2 # 第1因子、第2因子
国語 0.722
社会 0.730 0.268
数学 0.177 0.768
理科 0.156 0.654
英語 0.537 0.470
Factor1 Factor2 # 第1因子、第2因子
SS loadings 1.399 1.317 # 因子負荷の平方和(因子寄与)
Proportion Var 0.280 0.263 # 分散説明率(因子寄与率)
Cumulative Var 0.280 0.543 # 累積因子寄与率
Test of the hypothesis that 2 factors are sufficient. # 適合度判定
The chi square statistic is 0.08 on 1 degree of freedom.
The p-value is 0.782 # p値が小さい場合は「不適合」
この出力の最後に表示されたp値は、「適合度の検定」の結果を表しています。
この値は、いま試した「因子数=2」というモデルの「適合度」の値で、
(今までの場合と異なり)p値が大きいほど「適合している」、
p値が小さいと「適合していない」ということを表します。
そして有意水準より小さい場合は「適合していない」として棄却されます。
共通性とは「1から独自性を引いた値」で、因子により説明できる部分を表します。 つまり、共通性の値が大きければ大きいほど、因子によって説明できる部分が大きいことを表します。
> 共通性 <- ( 1-五教科因子分析$uniquenesses ) # uniqunesses は小文字から始まることに注意
> 共通性
国語 社会 数学 理科 英語
0.5288198 0.6049597 0.6213085 0.4523362 0.5087881
この例では、社会と数学が(それぞれ第1因子と第2因子に対応して)共通性の値が大きく、理科がほかと比べて小さいという結果が得られました。
また『因子負荷』とは、それぞれの観測変数による因子の貢献度を表す数値です。 因子1に対して国語と社会が大きいアタになっているのに対し、 因子2に対しては数学と理科が大きな値になっています。 これらにより「観測変数は因子2個のモデルで説明できる。因子1は国語と社会、 因子2は数学と理科に共通する要因とかんがえられる(英語はその両方)」 と解釈されます(これらに対して「文系因子」とか「理系因子」と名付けるのはセンスが必要でしょう)。
ここで、先の結果で、国語の行においてFactor2の値が表示されていないことについて補足しておきます。 値が表示されなかったのは、その値が小さかったからです。これを表示させるには、つぎのように cutoff=0 を指定します:
> print(五教科因子分析,cutoff=0)
Call:
factanal(x = 五教科, factors = 2)
Uniquenesses:
国語 社会 数学 理科 英語
0.471 0.395 0.379 0.548 0.491
Loadings:
Factor1 Factor2
国語 0.722 0.084
社会 0.730 0.268
数学 0.177 0.768
理科 0.156 0.654
英語 0.537 0.470
Factor1 Factor2
SS loadings 1.399 1.317
Proportion Var 0.280 0.263
Cumulative Var 0.280 0.543
Test of the hypothesis that 2 factors are sufficient.
The chi square statistic is 0.08 on 1 degree of freedom.
The p-value is 0.782
この結果の解釈については教科書を読んでください。