Rの基礎(3)
Rの基本的なデータ構造であるデータフレームと、基礎的な入出力とグラフィックスについて学びます
学習項目です
データフレーム: よく使われる基本データ構造
データフレームは、データ分析において最もよく使われるデータ構造である。
見かけは下のように行列と同じ2次元構造であるが、
| |
列1のラベル |
列2のラベル |
… |
列mのラベル |
| 行1のラベル |
要素1-1 |
要素1-2 |
… |
要素1-m |
| 行2のラベル |
要素2-1 |
要素2-2 |
… |
要素2-m |
| … |
… |
… |
… |
… |
| 行nのラベル |
要素n-1 |
要素n-2 |
… |
要素n-m |
以下の点が行列と異なる特徴である。
- 列データとして数値型や文字型など異なるデータ型のベクトルでよい、
- 各行および各列には「ラベル」(名称)を持ち、ラベルによって行や列、特定の要素にアクセスできる、
この特徴によって、すべての要素が同じ型でなければならない行列よりも使いやすい。
実際、実験データや調査データのようなデータを記憶するのがデータフレームの目的である。
例えば、学生の成績データを扱うとすれば、各行は個々の学生の成績、各列は国語や数学のような項目(変数)を表す。
Rに組み込みの変数iris(統計学者のFisherによるアヤメのデータ)の値は、調査した3種類のアヤメの萼片(Sepal)の長さと幅、花弁(Petal)の長さと幅、それにアヤメの種類(setosa, versicolor, virginicaの3種)についての150個のデータで、個々のアヤメが行、それぞれの特徴量が列で表されたデータフレームである。
ここで、関数headは、データフレームやベクトルの最初のいくつかを表示する関数である。なお、関数tailは逆にデータの最後の要素のいくつかを表示する関数である。
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
注意すべきは、データフレームは2次元構造なので、各列の要素数は同じでな
ければならないことである。また数値型データ以外は「因子型(factor)」に強制的に変換されることにも注意しよう。
データフレームの作成とラベル
データフレームを作成するには以下の例に上げるように、data.frame関数を使う。
作られたオブジェクトは行列と異なり、data.frame型となる。
> Namae <- c("太郎", "花子", "次郎", "直美")
> Math <- c(80, 90, 50, 60)
> English <- c(60, 80, 70, 90)
> Seiseki <- data.frame(namae=Namae, math=Math, eng=English)
> Seiseki
namae math eng
1 太郎 80 60
2 花子 90 80
3 次郎 50 70
4 直美 60 90
> class(Seiseki)
[1] "data.frame"
上記では関数data.frameの引数として「ラベル=ベクトル」が3つ使われていた。
ここで書かれたラベル(上記の例ではnamae, math, eng)がそれぞれの列を表す。
このラベルは、データフレーム(を記憶している変数)に$をはさんで書くことで、その列データを参照することができる。(行のラベルはここでは付けられていないことにも留意されたい)
--- 心としては、データフレームとは、
行で表されるいろいろなサンプルに対し、
列で表されるいろいろな特徴量の値を表にしたもの、
である。いわば、特徴量ごとのデータ(列ベクトル)の集合体とみなせる。
だから、データフレームは特徴量ごとのベクトルを集めたものとして作られ、
また特徴量ごとのベクトルを取り出しやすくなっているのである。
> Seiseki$math
[1] 80 90 50 60
> class(Seiseki$math)
[1] "numeric"
> Seiseki$namae
[1] 太郎 花子 次郎 直美
Levels: 花子 次郎 太郎 直美
> class(Seiseki$namae)
[1] "factor"
> class(Namae)
[1] "character"
この例でわかるように、文字列型であったnamae列のデータはデータフレームでは自動的に「因子(factor)型」に変換されている。因子型のデータを表示するときには、Levelsで示される行も表示されることに注意しよう。これは統計における「カテゴリ」が値であることを、カテゴリデータの一覧もあわせて表示することによって示すものである。
列の名前は次のように colnames関数で取り出すことができる。
> colnames(Seiseki)
[1] "namae" "math" "eng"
このデータフレームに新たに行のラベルをつけることができる。
行にはデフォルトとして数の名前が付けられており、
それを rownames関数で取り出すことができるが、
以下に示すように、行のラベル付けにもrownames関数を用いる。
(「行」にあたる英語が row 、「列」にあたる英語が column )
> rownames(Seiseki)
[1] "1" "2" "3" "4"
> rownames(Seiseki)<-c("Taro","Hanako","Ziro","Naomi")
> Seiseki
namae math eng
Taro 太郎 80 60
Hanako 花子 90 80
Ziro 次郎 50 70
Naomi 直美 60 90
データフレームの要素は、従来の「n行目のデータ」「m列目のデータ」「n行m列のデータ」という、行と列の番号による指定によってアクセスできる(もっともあまりお薦めしない)。
それに加えて、次のようにラベルを用いたアクセスもできる:
> Seiseki[,2]
[1] 80 90 50 60
> Seiseki$math
[1] 80 90 50 60
> Seiseki[3,2]
[1] 50
> Seiseki$math[3]
[1] 50
上で見たように、列ラベルによっていろいろなアクセスができるが、実は行ラベルはほとんど使い道がない。実際、特定の行を取り出すには、行番号による方法に加えて、次のように列ラベルを用いてアクセスするしかない:
> Seiseki[1,]
namae math eng
Taro 太郎 80 60
> Seiseki[Seiseki$namae=="太郎",]
namae math eng
Taro 太郎 80 60
> subset(Seiseki,namae=="太郎")
namae math eng
Taro 太郎 80 60
> Seiseki[Seiseki$math<=60,]
namae math eng
Ziro 次郎 50 70
Naomi 直美 60 90
> subset(Seiseki,math<=60)
namae math eng
Ziro 次郎 50 70
Naomi 直美 60 90
行列がある場合、それを用いてデータフレームを作ることもできる(Namae, Math, EnglishはデータフレームSeisekiを作るときに定義した変数)。
> Seiseki.matrix <- matrix(c(c(1,2,3,4), Math, English), 4, 3)
> ( Seiseki2 <- data.frame(Seiseki.matrix) )
X1 X2 X3
1 1 80 60
2 2 90 80
3 3 50 70
4 4 60 90
> Seiseki2$X2
[1] 80 90 50 60
> names(Seiseki2)<-c("namae","math","eng")
> Seiseki2
namae math eng
1 1 80 60
2 2 90 80
3 3 50 70
4 4 60 90
> Seiseki2$namae <- c("太郎","花子","次郎", "直美")
[1] "太郎" "花子" "次郎" "直美"
> Seiseki2
namae math eng
1 太郎 80 60
2 花子 90 80
3 次郎 50 70
4 直美 60 90
[なぜnamae列だけ別に値を与えたのか?]
最初に行列を作るとき
matrix(Namae, Math, English)で作れば簡単だったのでは、と思ったかもしれない。
> Seiseki.matrix.try <- matrix(c(Namae,Math,English),4)
しかし、その値をみてみると、すべて文字型に変換されている。これは、行列がの要素がすべて「同じ型」でなければならないという制約から、自動的に変換されたからである。
> Seiseki.matrix.try
[,1] [,2] [,3]
[1,] "太郎" "80" "60"
[2,] "花子" "90" "80"
[3,] "次郎" "50" "70"
[4,] "直美" "60" "90"
> ( Seiseki.try <- data.frame(Seiseki.matrix.try) )
X1 X2 X3
1 太郎 80 60
2 花子 90 80
3 次郎 50 70
4 直美 60 90
> class(Seiseki.try$X3)
[1] "factor"
> class(Seiseki$eng)
[1] "numeric"
> Seiseki.try$X2 <- as.numeric(Seiseki.try$X2)
> Seiseki.try
X1 X2 X3
1 太郎 3 60
2 花子 4 80
3 次郎 1 70
4 直美 2 90
上記のように、一つでも文字型の値があると全体が因子型に変換されるため、一見同じものに見えても、実際は異なるデータとなってしまう。これがnames列に最初、数値型の値を与えておいて、後で文字型の値を代入した理由である。
課題1-1
次はA組とB組の物理学の点数である。
A組: 52 86 41 64 33 19 65 35 48 15
B組: 42 59 32 54 35 45 35 55 49 41
これからデータフレームを作り、変数Buturiに代入せよ。ただし、列の名前をそれぞれAとBとする。そして、A組の平均値と不偏分散、B組の平均値と不偏分散を求めるコード(プログラム)を書き、値を求めよ。
[課題1-1の答え]
> ( Buturi <- data.frame(A=c(52, 86, 41, 64, 33, 19, 65, 35, 48, 15),
B=c(42, 59, 32, 54, 35, 45, 35, 55, 49, 41)) )
A B
1 52 42
2 86 59
3 41 32
4 64 54
5 33 35
6 19 45
7 65 35
8 35 55
9 48 49
10 15 41
> paste("A組の平均=",mean(Buturi$A),"A組の不偏分散=", var(Buturi$A))
[1] "A組の平均= 45.8 A組の不偏分散= 481.066666666667"
> paste("B組の平均=",mean(Buturi$B),"B組の不偏分散=", var(Buturi$B))
[1] "B組の平均= 44.7 B組の不偏分散= 87.3444444444444"
課題1-2
課題1-1の変数Buturiを用いる。A組で60点未満のものの人数(個数)を求めるコードを書け。また、60点未満の点数を表示するコードを書け。
[課題1-2の答え]
> length(Buturi[Buturi$A < 60,]$A)
[1] 7
> Buturi[Buturi$A < 60,]$A
[1] 52 41 33 19 35 48 15
length(Buturi[Buturi$A < 60,])では不正解(この場合2次元データなので、lengthは行の個数ではなく列の個数を返す)。ただし、nrow(Buturi[Buturi$A < 60,])なら正解。
課題1-3
- 課題1-1の変数Buturiを用いる。奇数番号の者はEngコース("Eng"で表す)、
偶数番号の者はTechコース("Tech"で表す)であった。
この情報をButuriに加えた新たなデータフレーム Data を作れ。
- Engコースのものの情報だけ取り出し、変数 eng の値とせよ。
- EngコースのA組の平均と不偏分散を求めよ。
[
課題1-3の答え]
(1)は、Buturiのデータを元にdata.frame関数を使って作りなおす。
ここで、Rの基礎(1)で出てきたrepが使えるとやりやすいだろう。
(2)は、課題1-2と同じ「条件を指定した要素の取り出し」である。
ここではカンマが重要である(これがないとどうなるだろう、
またそれはなぜだろう?)
ここまでできれば(3)は簡単。
> Data <- data.frame(A=Buturi$A, B=Buturi$B,
course=rep(c("Eng","Tech"),5))
> Data
A B course
1 52 42 Eng
2 86 59 Tech
3 41 32 Eng
4 64 54 Tech
5 33 35 Eng
6 19 45 Tech
7 65 35 Eng
8 35 55 Tech
9 48 49 Eng
10 15 41 Tech
> eng <- Data[Data$course=="Eng",]
> eng
A B course
1 52 42 Eng
3 41 32 Eng
5 33 35 Eng
7 65 35 Eng
9 48 49 Eng
> paste("平均=",mean(eng$A),"不偏分散=",var(eng$A))
[1] "平均= 47.8 不偏分散= 144.7"
入出力
入出力とは、キーボードやファイルなどからRのプログラムにデータを送る「入力」と、Rのプログラムから画面やファイルにデータを送る「出力」が合わせたものを指す。ここでは出力と入力の順に説明する。
出力用の関数としてprintがあるが、これは普通のプログラミング言語の出力とは少し違うものである。Rにおける出力は前のページで述べたcat関数が担当する。
cat関数はいくつでも引数をとることができ、その値を文字列として表示する。
引数の間はデフォルトでは1個のスペースが入るが、sep=値によって、引数の間にいれる文字(仕切り文字という)を変えることができる。
デフォルトでは改行を行わないので、改行を行いたい場合は"\n"という文字列をcatの引数に含める。なお"\t"を指定すれば、タブがはたらく。
> cat("This is a test.")
This is a test.>
> cat("This is another","test.\n")
This is another test.
> i <- 10; cat("\ti =",i,"\tOK\n")
i = 10 OK
関数readlineによってキーボードからの入力を一つの文字列として変数に代入することができる。引数としてprompt=文字列を指定することで、入力を促す記号(promptという)をつけることができる。
> inStr <- readline()
これはRへの入力テストです。
> inStr
[1] "これはRへの入力テストです。"
> inStr <- readline("入力をどうぞ> ")
入力をどうぞ> 1 2 3
> inStr
[1] "1 2 3"
Rでは文字列を扱う関数が用意されているものの、文字列データよりも数値型データの方が扱う対象としては主流である。上記でみてわかるように、数を入力してもreadlineではひとまとめの文字列になっているので、Rプログラムとしてはあまり使い道がない。
[文字列をベクトルにする方法]
Rでは文字列を処理する関数がいろいろある。その一つの
strsplitを使って
"1 2 3 4 5"という文字列を数値型の要素のベクトルに変換する方法を例によって示す。
> inStr <- "1 2 3 45 67 890"
> strsplit(inStr," ")
[[1]]
[1] "1" "2" "3" "45" "67" "890"
> unlist(strsplit(inStr," "))
[1] "1" "2" "3" "45" "67" "890"
> as.numeric(unlist(strsplit(inStr," ")))
[1] 1 2 3 45 67 890
scanは、(主として)数値型データを入力するための関数である。次の例のように、デフォルトでは数値以外のデータが入力されるとエラーになる。
> inData <- scan()
1: 10 20 30 -50 -20 0
7:
Read 6 items
> inData
[1] 10 20 30 -50 -20 0
> dame <- scan()
1: 1 2 a b
以下にエラー scan(file, what, nmax, sep, dec, quote, skip, nlines, na.strings, :
scan() 関数は 'a real' を期待したのに、得られたのは 'a' でした
ファイルの操作
一般のプログラミング言語では、ファイルからデータを読み込んだりデータを書き出したりするには、(1)ファイルを開く、(2)入出力コマンドを使ってファイルにアクセスする、(3)ファイルを閉じる、という3ステップが必要である。
Rでも「コネクション」という概念により上記のことを行うこともできるが、(1)から(3)まで一遍に「入出力コマンド」でやってしまうこともできるようになっている。
まず入力について説明する。
関数readLinesは、第1引数(引数名はcon)にファイル名(ちゃんと書くと、作業ディレクトリからファイルへのパス)、第2引数(引数名はn)に読み込む行数(省略時はすべて)をとり、そのファイルから指定された行数の文字列をベクトルとして返す。
> ( lines <- readLines("Rintro-03.html",3) )
[1] "<html>"
[2] "<head>"
[3] " <meta http-equiv=\"Content-Type\" content=\"text/html; charset=EUC-JP\">"
「入力」の項で書いたように、Rではこのような文字列の入力は実際にはあまり使わないであろう。これに対して、ファイルからデータを読み込み「データフレーム」として記憶するのに使われる関数がよく使われる。
関数read.tableと関数read.csv, 関数read.csv2がその典型である。これらはいずれもCSV(Comma Separated Values)形式のファイルを読み込み、データフレームを返す関数である。これらの違いは、要素と要素の間の区切り文字がread.tableでは空白(スペースやタブ)、read.csvではコンマ(, )、read.csv2ではセミコロン(;)と仮定されていることである。しかし実際には引数名sepの値を指定することで区切り文字は変更可能である。
CSVファイルの例としては、次にあげるtest.csv(区切り文字としてタブが使用されている)やtestC.csv(区切り文字はコンマ)があげられる。
[CSVファイルとは]
CSV形式のファイルは、項目が区切り文字(典型的にはコンマ「,」)により区切られた行からなるテキストファイルである。ファイルの拡張子として .csvが使われる。項目の中に区切り文字が現れる場合は項目全体を引用符(二重引用符(")、もしくは一重引用符('))でくくる。
区切り文字としてはコンマを使うのがCSVの名前の由来であるが、スペースやタブ(まとめて「空白」と呼ぶ)、セミコロン(;)が使われることもある。なお、Excelでは「CSV(コンマ区切り)に保存」を選ぶとデータがCSVファイルに変換される。
読み込み対象のファイルの第1行目は列の名前が書いてあるヘッダーとしてみなされるのがデフォルトである。ただし、それには条件があり、第1行目「だけ」他の行と項目数が1個少なくなければならない。そうでなければ(つまり、他の行と同じ個数の項目があった場合)、
引数名header=TRUEを指定すれば、ファイルの第1行目が列の名前(colnames)であるとみなされる。なお、ファイルにヘッダーがなく引数名col.namesに列の名前ベクトルが指定されていなければ、列の変数はV1, V2, ....という名前となる。
################# test.csvの内容: (要素の区切りはタブ)#######################
height weight gender
Taro 180 80 male
Hanako 160 45 female
Ziro 170 65 male
############### testC.csv2の内容: (要素の区切りはコンマ) ####################
height,weight,gender
Taro,180,80,male
Hanako,160,45,female
Ziro,170,65,male
> (inData <- read.table("test.csv") )
height weight gender
Taro 180 80 male
Hanako 160 45 female
Ziro 170 65 male
> class(inData)
[1] "data.frame"
> rownames(inData)
[1] "Taro" "Hanako" "Ziro"
> colnames(inData)
[1] "height" "weight" "gender"
> dim(inData)
[1] 3 3
> ( inDataX <- read.table("test.csv",col.names=c("身長","体重","性別")) )
身長 体重 性別
Taro 180 80 male
Hanako 160 45 female
Ziro 170 65 male
> ( xxx <- read.csv("test.csv") )
height.weight.gender
1 Taro\t180\t80\tmale
2 Hanako\t160\t45\tfemale
3 Ziro\t170\t65\tmale
> ( xxx <- read.csv("test.csv",sep="") )
height weight gender
Taro 180 80 male
Hanako 160 45 female
Ziro 170 65 male
> ( inDataC <- read.csv("testC.csv") )
height weight gender
Taro 180 80 male
Hanako 160 45 female
Ziro 170 65 male
今度は、ファイルにデータを書出す関数を紹介する。そのひとつは既に見た関数catである。引数としてfile="ファイル名"を与えることで、Rのオブジェクトの値をファイルに書出す。今まで見ていたのはこの指定がないため、標準出力(つまり画面)に出力するものであった。
ただし、catは自動的には改行しないため、ファイルに書出す場合は特に改行文字"\n"を出力することを忘れないようにしよう。また、行列やデータフレームなど2次元以上のデータはcatでは出力に適さないことにも注意。
> one <- 1:10
> cat(one,file="sample.txt")
> readLines("sample.txt")
[1] "1 2 3 4 5 6 7 8 9 10"
警告メッセージ:
In readLines("sample.txt") :
'sample.txt' で不完全な最終行が見つかりました
> cat(one,"\n",file="sample.txt")
> readLines("sample.txt")
[1] "1 2 3 4 5 6 7 8 9 10"
> cat(inData,"sample.txt")
以下にエラー cat(list(...), file, sep, fill, labels, append) :
引数 1 (タイプ 'list') は 'cat' で取り扱えません
> ( x <- matrix(1:12,3,4) )
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> cat(x,file="sample.txt")
> readLines("sample.txt")
[1] "1 2 3 4 5 6 7 8 9 10 11 12"
警告メッセージ:
In readLines("sample.data") :
'sample.data' で不完全な最終行が見つかりました
ファイルからの入力のところで書いたように、Rでは文字列をファイルに書き込んだり、ファイルから文字列を読み込むことはあまりない。やはりいちばん多い用途は、データフレームをファイルに書き込んだり、ファイルから読み込むことである。読み込みはread.tableなどでできることは既に見た。この反対の書き込みを行うのは、write.tableやwrite.csv、write.csv2関数である。
write.tableとwrite.csvとwrite.csv2の関係は、read.tableとread.csvとread.csv2と同じ、つまり項目の区切り文字の違いである。
write.tableは2つの引数をとり、1番目の引数はデータフレームか行列をとる。また、2番目(引数名はfile)に書き込むファイル名を指定する。
> write.table(inData,"sample.csv")
> read.table("sample.csv")
height weight gender
Taro 180 80 male
Hanako 160 45 female
Ziro 170 65 male
> write.table(matrix(11;22,3,4),"sample.csv")
> read.table("sample.csv")
V1 V2 V3 V4
1 11 14 17 20
2 12 15 18 21
3 13 16 19 22
[Excelファイルを読み込む方法]
Excelを使って表形式のデータを作ることはよく取られる方法である。そうして作ったデータをRに取り込みたいと思うのも自然である。それには、既に紹介したようにExcelで「CSV(コンマ区切り)に保存」を選べばCSV形式のファイルになる。
しかし時にはExcelが提供する形そのままのファイル(90年代では拡張子がxls、2000年代ではxlsx)をRに取り込みたいと思うかもしれない。
そのためには、gdataライブラリを用いる。ただしそのためにはプログラミング言語Perlが必要であることと、gdataパッケージをインストールしておくこと、
それにinstallXLSXsupportを実行しておく必要が有る。
(注:これらの準備が必要なために、コンピュータ演習室のコンピュータではxls形式のExcelファイルの読み込みはできない)
それらの準備ができたなら、次のようにすればExcelのファイルを読み込むことができる。ただし、最初のlibrary(gdata)は1回だけ実行すれば良い。以下では、
PerlがC:/Perl64/bin/perl.exeにあるとして実行している。
> library(gdata)
> installXLSXsupport(perl="C:/Perl64/bin/perl.exe")
> ( x <- read.xls("sample.xlsx") )
X V1 V2 V3 V4
1 1 1 4 7 10
2 2 2 5 8 11
3 3 3 6 9 12
> ( x <- read.xls("sample.xlsx", sheet=2) )
Rで作業して作られた関数や変数の名前は、関数lsでみることができる。
ただしこれには組み込みの関数やライブラリは現れない。
> ls()
[1] "English" "indData" "inDataC" "lines"
[5] "Math" "Name" "one" "Seiseki"
[9] "x" "xxx"
作業スペース(Rで作業してきた変数や関数などのライブラリも含めた情報)をすべて保存するには関数save.imageを、特定の変数や関数を保存するには関数saveを用いる。また復元には関数loadを用いる:
> save(x,y,inData,Seiseki,file="save.data")
> rm(x, y, inData, Seiseki)
> class(x)
エラー: オブジェクト 'x' がありません
> load("save.data")
> x
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> save.image("save.data")
> load("save.data")
> x
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
課題2-1
次は課題1-1で出した、A組とB組の物理学の点数である。
A組: 52 86 41 64 33 19 65 35 48 15
B組: 42 59 32 54 35 45 35 55 49 41
課題1-1では列の名前をそれぞれAとBとし、変数Buturiにこのデータフレームを代入した。
このことを前提として、この課題では次のことを行え:
- buturi.csvというファイルに、このButuriのデータを書き込め。
[ファイルに書き出すときの注意]
コンピュータ演習室の環境では、デフォルトでは、読み込み・書き込みされるファイルは "C:/Windows/system32" にあるものとされています。このフォルダのことを「(作業用」ディレクトリといい、Rから、
getwd()
ここで、"C:/Windows/system32" は「管理者」だけが使えるフォルダなので、そこにファイルをつくろうとすれば、エラーになります。そこで、ファイルに書き込むには、
ディレクトリを変更し、作業用ディレクトリを自分が書き込んで良いフォルダにしなければなりません。それには次のようにします:
「ファイル」メニューから「ディレクトリの変更」を選び、
コンピュータ演習室ではHドライブ(またはその下のどこかのフォルダ)を選択して、OKをクリックする
なお、
getwd()を使って、ディレクトリが変更されていることの確認も忘れないようにしてください。
- rm(Buturi)を実行し、Buturiという変数が消去されたことを確認せよ。
- buturi.csvファイルからデータフレームを読み込み、変数Buturiに代入し、値が前のものと一致しているかどうかを確かめよ。
- 変数Buturiをsaveを用いてButuriSaved.dataファイルに保存せよ。
- 再度rm(Buturi)を実行し、Buturiという変数が消去されたことを確認せよ。
- ButuriSaved.dataファイルからButuri変数を復元し、前の値と一致するかどうか確かめよ。
[
ヒントと一部の解答]
与えられたデータフレームを変数Buturiに代入するには次のようにする(課題1-1の解答):
Buturi <- data.frame(A=c(52, 86, 41, 64, 33, 19, 65, 35, 48, 15),
B=c(42, 59, 32, 54, 35, 45, 35, 55, 49, 41))
これをbuturi.csvというファイルに書き込むには次のようにする(注意:どのフォルダーに書き込むか、確認しておくこと。
それには「Rの基礎(4)」で紹介する
getwdが使える):
write.table(Buturi,"buturi.csv")
Buturiという変数が消えたかどうかは、
lsを用いても良いが、直接Buturiと打ち込んで
「 エラー: オブジェクト 'Buturi' がありません 」というメッセージによっても確認できる。
buturi.csvからデータフレームを読み込み、変数Buturiに代入するには read.tableを用いる:
Buturi <- read.table("buturi.csv")
なお、save関数を用いて作られたファイルの中身は read.table では読み込めない(読み込んでも、無意味なデータが得られる)。
save関数によって作られたファイルはload関数を用いて、データを読み込むこと。
データを視覚化することの重要性がますます高まっている。Rはそのためのとてもよい道具である。
どのようなことができるかは次のコマンドを試してみれば良い:
demo(graphics)
demo(image)
demo(plotmath)
example(barplot)
これらは実行しながらソースコードも表示する。気に入ったものがあれば、そのコードを真似すればよい。
表示されるグラフィックスは、Windowsシステムの場合、「ファイル」メニューから「クリップボードにコピー」が可能である。これにより、WordやPowerPointなどの文書に貼り付けできる。また、同じく「ファイル」メニューから「別名で保存」を選ぶと、PDFやPostScript、PNG などの画像ファイルを作ることができる。
基本のグラフィックス関数
関数plotはよく用いられるデータ表示のための関数である。基本形は次のとおりである:
plot(数値ベクトル)
plot(横軸の値となるベクトル, 縦軸の値となるベクトル)
plot(データフレーム)
plotはデフォルトでは「点」(デフォルトでは○)で該当するデータを表示する。これをなめらかに「線」でつなぐにはtype="l"というオプションを用いる。また、○ではなく他の文字や記号で表示するにはpch="+"のようなオプションを用いる。
plot(sin(seq(0,2*pi,0.1)))
plot(sin(seq(0,2*pi,0.001)))
plot(sin(seq(0,2*pi,0.1)),type="l")
A <- c(52, 86, 41, 64, 33, 19, 65, 35, 48, 15)
B <- c(42, 59, 32, 54, 35, 45, 35, 55, 49, 41)
plot(A, B, pch="*")
plot(iris)
plotには色を指定するcol引数などいろいろなオプションがある。マニュアルなどでplotのオプションについて調べてほしい。
課題3-1
graphicsとimageのデモを実行してみよ。また、それぞれの実行中に表示されるコードの中から一つ選び、そのコードをデモとは別に実行し、その画像をPNGファイルにせよ。
課題3-2
plotの説明であげたコードを実行せよ。また、plotのtypeとpchの値の候補としてどのようなものがあるか調べ、いろいろ変えて実行してみよ。
このページで出てきたRの関数や記号
- データの一部表示: head, tail
- データフレーム: data.frame, names, rownames, subset
- 入力: readline, scan
- 出力: cat, print
- ファイルからの入力: readLines, read.table, read.csv, read.csv2
- ファイルへの出力: cat, write.table, write.csv, write.csv2
- Excelファイルの入力(注意:コンピュータ演習室のPCではできない): gdataライブラリ, read.xls
- Rの作業スペース関連: ls, rm, save.image, save, load
- 簡単グラフィックス: demo, example, plot
演習問題
Rで関数のグラフを書くことを演習を通して学ぼう。
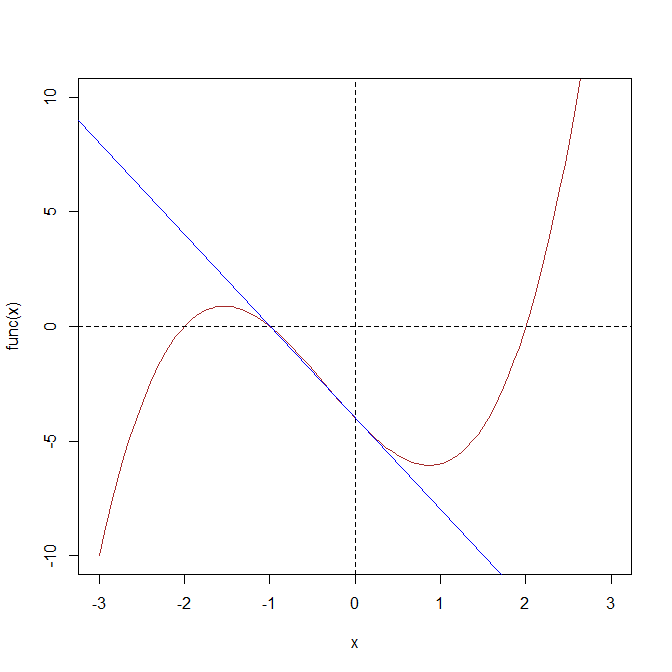
右の図で示されるグラフを書こう。これは3次関数で与えられる曲線と1次関数で与えられる直線を表示したものである。それにくわえてx軸とy軸に相当する直線を点線で表示してある。
(1) この図で示された曲線の式は
y = x3+x2-4x - 4
である。そこで、
func(x)= x3+x2-4x - 4という数学関数をRで表わせ。(ヒント: 引数を一個とる関数として書ける。つまり、
func <- function(x) { ... } という形である)
(2) Rの関数curveによりグラフを表示する。
ここでcurve(expr,from,to)は第1引数(expr)として曲線の式をとり、第2引数(from)と第3引数(to)は、表示すべき関数の定義域(xの値の最小と最大)を指定する。
例えば、定義域が-3から3までの標準正規分布(平均0, 分散1の正規分布/ガウス関数)は次のようにして描くことができる:
curve(dnorm(x), -3, 3)
この例に従い、定義域(
xの範囲)を-3から3までとして、(1)で定義した関数
funcのグラフを描け。
(3) このままでは、描画したグラフには、原点を通りx軸とy軸にそれぞれ平行な線が引かれないままである。そこで、
次のようにablineを用いてこの2つの線を加えることにする。ここで、lty=2
は、点線で線を表示することを意味する(1なら実線、3なら一点鎖線)。
(func関数のグラフを消してしまっているのなら再度 (2)を実行した後、)以下を実行して、先のグラフにx軸とy軸を表す直線を加えた表示を作れ(なお#以降はコメントなので入力不要である) 。
abline(h=0, lty=2)
abline(v=0, lty=2)
(4) この3次関数のグラフに対し、x=0における接線を引く。その接線の式を求めよ (ヒント:接線の傾きは、微分の値に等しい) 。その式が定数a,bを用いて
y=bx+aと表されるとすると、
このグラフは(またもや)
abline(a,b)で表示される。ここで線の色はデフォルトでは黒であるが、それを青色(blue)に変えるには
col="blue"を引数に加えて、
abline(a,b,col="blue")とすれば良い。このことを利用して、青色でx=0における接線を表示せよ。
(1)
指定されたファイル(出典:総務省統計局、日本の統計「身長と体重の平均値」)を読み込み、変数
dataの値とする(型はデータフレームとせよ)。(ヒント: 指定されたファイルをダウンロードする。これは「コンマを区切り記号とする」csvファイルである。Rの関数を用いてそのファイルを読み込む)
[ファイルをRから開くためのヒント]
コンピュータ演習室では、ファイルの置き場所に注意しないと、Rのから読み込みにくいことがある(自宅のコンピュータならすぐできることが、演習室のコンピュータでは管理者権限がないため難しくなっている)。
ここではコンピュータ演習室で作業する人のためのヒントを書く。
まず、ファイルをHドライブ(など、自分に割り当てられたフォルダ)にセーブする。
次に、Rの「ファイル」タブから「ディレクトリの変更」を選び、ファイルを置いたフォルダを指定する。
これは、Rに対し、あなたがおいたファイルの場所を教えるためである
(この作業は、自宅のコンピュータでも必要であろう)。
最後に、解説で述べたread.csv関数を用いて、Rにデータを取り込む。
以下はdataの最初の数行を表示したものである:
(注意: このように表示されない場合は、関
数もしくは区切り記号の指定が間違っている。
秀丸エディタやTeraPadなどで読み込み対象のファイルを開き、
データどデータがどのような記号で句切られているかを確認すること。
可能性がある区切り記号は、スペース、タブ、コンマ、
セミコロンの4種類であり、それによって使う関数を選べ)
> head(data)
height weight sex year
1 79.6 11.0 M 2001
2 90.1 13.3 M 2001
3 96.8 14.9 M 2001
4 103.9 16.5 M 2001
5 109.6 18.7 M 2001
6 116.6 21.9 M 2001
(2)dataから、sexの値が"M"(男性を意味する)のものを取り出し変数maleの値とせよ。同
様に、sexの値が"F"(女性を意味する)のものを取り出し、変数femaleの値とせよ。
以下はmaleとfemale、それぞれの最初の数行を表示したものである:
> head(male)
height weight sex year
1 79.6 11.0 M 2001
2 90.1 13.3 M 2001
3 96.8 14.9 M 2001
4 103.9 16.5 M 2001
5 109.6 18.7 M 2001
6 116.6 21.9 M 2001
> head(female)
height weight sex year
63 79.0 10.1 F 2001
64 87.6 12.3 F 2001
65 95.2 14.1 F 2001
66 103.1 16.8 F 2001
67 109.5 18.7 F 2001
68 114.0 20.4 F 2001
[
データフレームから特定の条件を満たす要素を取り出す]
課題1-2と課題1-3 をやっておこう。
(3)maleの各行に対し、weight列の値をx座標、height列の値をy座標とする点を青色で表示せよ。ここで表示にはplotを用いよ。
(4)femaleの各行に対し、weight列の値をx座標、height列の値をy座標とする点を赤色で表示せよ。ここで表示にはplotを用い、(3)のグラフの上に重ねて表示させよ。
ここで「グラフを重ねて表示」するには、1つグラフを表示させた後に
par(new=T)を実行してから、もう一つのグラフを表示させる。
なお、同様にして、幾つものグラフを重ね合わせて表示させることができる。
(5)(4)を実行させると、x軸やy軸の表示が微妙にずれていることに気づくだろう。これはそれぞれのグラフで横軸と縦軸の調整を別々に行っているからである。
これを防ぐには、plotにxlim=c(0,100), ylim=c(80,180)という引数を加えるとよい。これにより、強制的にx(この場合はweight)の範囲が0から100、
y(この場合はheight)の範囲が80から180に調整される。実際にこれを試してみよ。
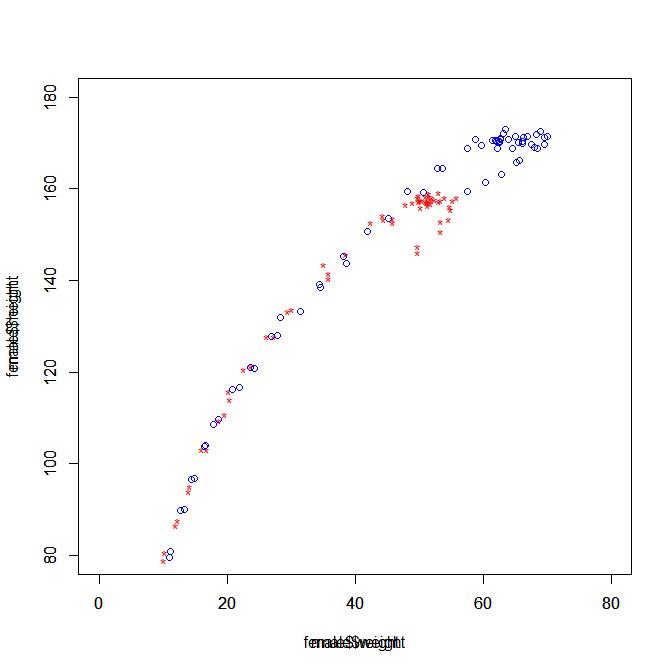 (6)2つのグラフはともに○でプロットされるため、色がついていても判別が難しい。
そこで「基本的なグラフィックス」節で述べたpch引数を使って、女性と男性が判別しやすいように表示を工夫せよ。その一例が
右図である。
(6)2つのグラフはともに○でプロットされるため、色がついていても判別が難しい。
そこで「基本的なグラフィックス」節で述べたpch引数を使って、女性と男性が判別しやすいように表示を工夫せよ。その一例が
右図である。
(7)得られた図は、まだまだ工夫が必要かもしれない。どのような図がよいか、
またそれにはどうしたらできるだろうか、考えを述べよ。
前の解説を見る トップページに戻る 次の解説を見る